How to convert string to token in Java?
How to convert string to token in Java?
Converting a string to tokens in Java can be achieved using various techniques. Here are a few approaches:
Split Method: Thesplit() method is the simplest way to split a string into tokens. It takes a regular expression as an argument and returns an array of strings.
String str = "Hello, World! This is a test.";
String[] tokens = str.split("[ ,.!]+");

In this example, the split() method splits the string at each occurrence of comma, space, period, or exclamation mark. The result is an array of tokens: ["Hello", "World", "This", "is", "a", "test"].
StringTokenizer (although this class is considered obsolete) or StreamTokenizer (part of the Java 2 SDK).
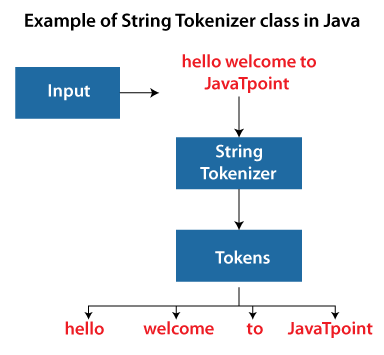
Here's an example using StringTokenizer:
String str = "Hello, World! This is a test.";
StringTokenizer tokens = new StringTokenizer(str, "[ ,.!]+");
while (tokens.hasMoreElements()) {
System.out.println(tokens.nextElement());
}
Here's an example:
String str = "Hello, World! This is a test.";
List tokens = Arrays.stream(str.split("[ ,.!]+"))
.map(String::trim)
.collect(Collectors.toList());
tokens.forEach(System.out::println);
In this example, we use the stream() method to create a stream of strings from the original string. Then, we filter out empty strings using the map() method and convert them to lowercase using the String::toLowerCase() method. Finally, we collect the filtered tokens into a list using the collect() method.
Pattern.compile() and Matcher classes.
Here's an example:
String str = "Hello, World! This is a test.";
Pattern p = Pattern.compile("[^a-zA-Z]+");
Matcher m = p.matcher(str);
while (m.find()) {
System.out.println(m.group());
}
In this example, we compile a regex pattern that matches any character that's not a letter (using the [^a-zA-Z]+ expression). Then, we use the matcher() method to create a matcher for our string. Finally, we iterate through the tokens found by the matcher using the find() and group() methods.
Each of these approaches has its own strengths and weaknesses. When choosing the best way to convert a string to tokens in Java, consider factors like performance, readability, and the complexity of your tokenization requirements.
StringTokenizer Java example
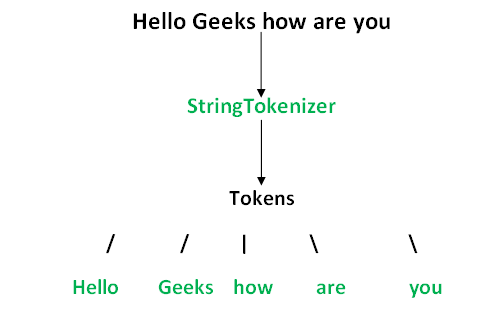
I'd be happy to help!
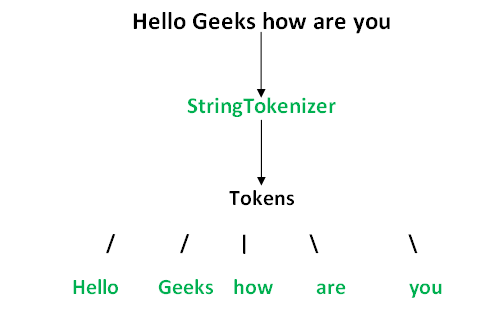
A StringTokenizer is a class that breaks a string into tokens (substrings) based on certain criteria, such as whitespace or a specific delimiter. It's an older API that has been largely replaced by the Splitter and Stream classes in Java 8.
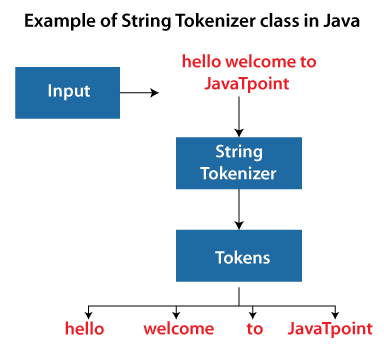
Here's an example of how to use StringTokenizer:
import java.util.StringTokenizer;
public class Main {
public static void main(String[] args) {
String str = "Hello, World! This is a test.";
StringTokenizer tokenizer = new StringTokenizer(str, ", ");
while (tokenizer.hasMoreElements()) {
System.out.println("Token: " + tokenizer.nextToken());
}
}
}
In this example, we create a StringTokenizer object with the string "Hello, World! This is a test." and the delimiter ", ". The hasMoreElements() method returns true if there are more tokens to be processed. If so, we call the nextToken() method to get the next token.
Here's the output:
Token: Hello
Token: World!
Token: This
Token: is
Token: a
Token: test.
As you can see, each token represents a single word or phrase from the original string. We can use StringTokenizer in various applications where we need to process text data by breaking it down into smaller parts.
Some of the benefits of using StringTokenizer include:
However, there are some limitations to consider:
Case sensitivity: By default,StringTokenizer is case sensitive. For example, if we have a string with both lowercase and uppercase letters, they will be treated as separate tokens. No support for regex: Unlike newer classes like Splitter, StringTokenizer doesn't support regular expressions (regex) for tokenization. Old API: As mentioned earlier, this class is an older API that has been replaced by more modern approaches.
In summary, StringTokenizer is a useful tool for breaking strings into tokens based on specified delimiters. While it's easy to use and efficient, it does have some limitations. In general, I recommend using newer classes like Splitter or Stream for most string processing tasks in Java 8 and later versions.