Apache Spark Java API
Apache Spark Java API
Apache Spark is a unified analytics engine that integrates various data sources and allows for large-scale data processing using Java. The Java API, also known as the Spark Java API, provides a set of classes and methods that enable developers to write applications in Java that can take advantage of the scalability and performance of Spark.
The Spark Java API is part of the Apache Spark ecosystem, which includes languages like Scala, Python, R, and SQL. However, using Java, you can leverage the power of Spark for data processing, machine learning, and streaming analytics.
Here are some key features of the Spark Java API:
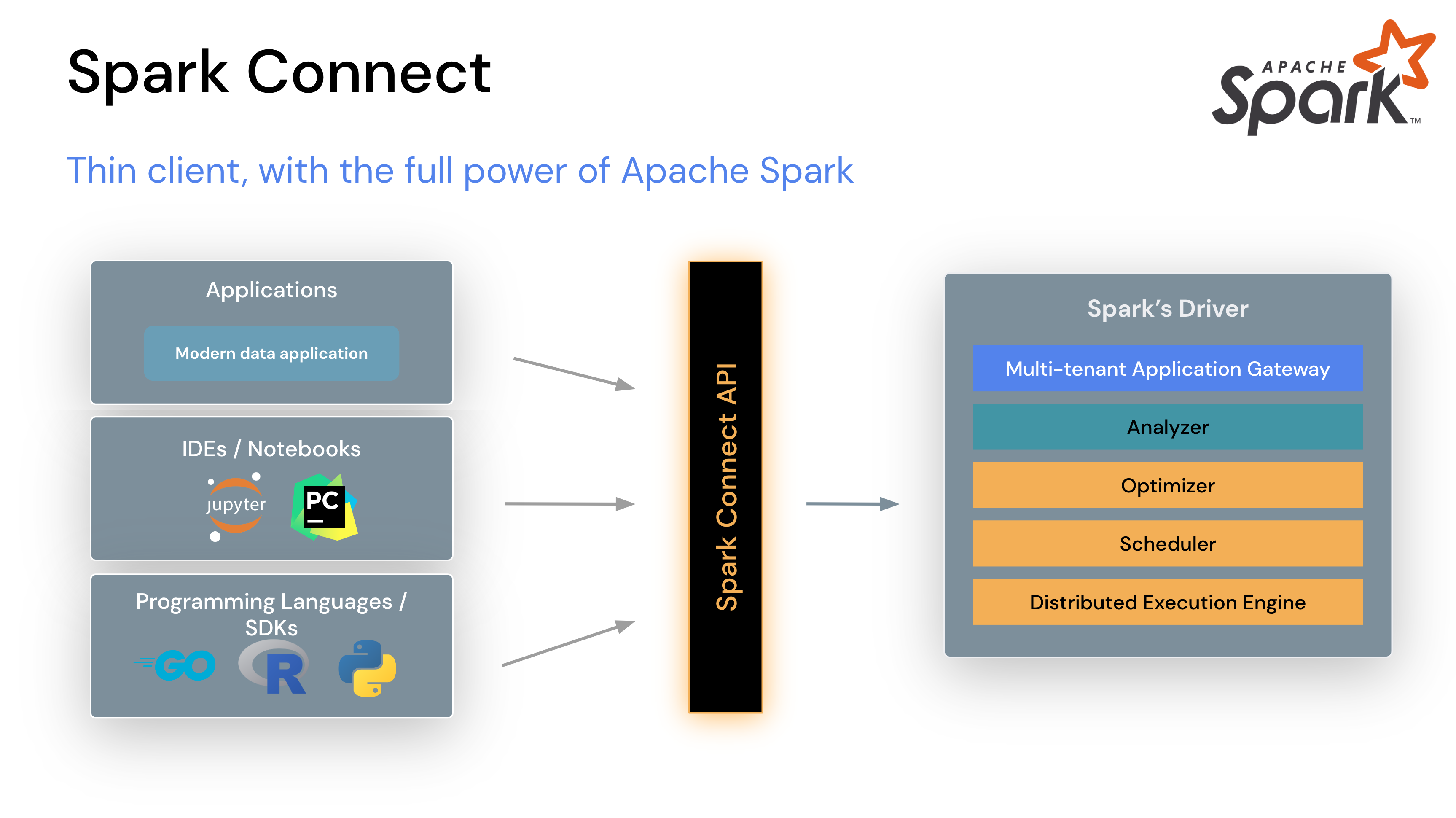
SparkConf: This class allows you to configure the Spark context and set various options like the number of cores or the spark.ui.port. JavaRDD<T>: This class represents a Java-based RDD that can be used to create an RDD from a collection of objects, such as a Java array or list. Java Functions: You can use Java functions to map and transform your data using Spark's APIs. These functions can be used with DataFrames and Datasets to perform various operations like filtering, sorting, and grouping. Machine Learning: Spark provides an MLlib library that includes various machine learning algorithms such as decision trees, random forests, and gradient boosting machines. You can use these algorithms for tasks like regression, classification, clustering, and topic modeling. Streaming: Spark's Streaming API allows you to process data in real-time using Java. You can create streaming sources and sinks, handle events and streams, and perform various processing operations on your data. SQL: The Spark SQL API provides support for Structured Query Language (SQL) queries. You can use SQL to query structured data stored in DataFrames or Datasets.
Here's a basic example of how you might use the Spark Java API:
SparkConf conf = new SparkConf().setAppName("Simple Application");
JavaSparkContext sc = JavaSparkContext.fromSparkConf(conf);
// Create an RDD from a list of strings
List words = Arrays.asList("hello", "world", "spark");
JavaRDD wordRDD = sc.parallelize(words);
// Transform the RDD using a map function
JavaRDD mappedRDD = wordRDD.map(word -> word.toUpperCase());
// Collect the results and print them to the console
List results = mappedRDD.collect();
System.out.println(results);
This example demonstrates creating an RDD from a list of strings, transforming it using a map function, and collecting the results.
apache/spark java github
I'd be happy to help with that! Here's a response in English:
Apache Spark is an open-source data processing engine that originated from UC Berkeley's AMPLab and is now used by thousands of organizations around the world. It provides high-level APIs in Java, Python, and Scala, as well as a rich set of libraries and tools to work with large-scale datasets. One of the primary goals of Spark is to provide a unified platform for various types of data processing tasks, such as batch processing, streaming, graph processing, and machine learning.
Apache Spark has many advantages, including:
High-performance processing: Spark's in-memory computing capabilities enable it to process large datasets quickly and efficiently. Flexibility: Spark can be used for a wide range of applications, from data processing and analysis to machine learning and artificial intelligence. Scalability: Spark is designed to handle large-scale data processing tasks and can scale up or down as needed. Integration: Spark integrates seamlessly with many other big-data technologies, including Hadoop, Hive, and Cassandra.To use Apache Spark in Java, you'll need to:
Download and install the Spark JAR file from the official Apache Spark website. Import the necessary classes and interfaces from the Spark API, such asSparkSession and Dataset. Use the SparkContext object to create a Spark session, which is used to execute Spark operations. Write Java code using the Spark API to process your data, such as by creating DataFrames, performing operations on them, and writing results to disk or other storage systems.
GitHub is a popular online platform for software development collaboration and version control. You can use GitHub to store and manage your Apache Spark projects, as well as collaborate with others on code development. To get started with using GitHub for Spark development:
Sign up for a GitHub account if you haven't already. Create a new repository for your Spark project and add the necessary files (such as your Java code and any data files). Use Git to track changes to your repository and collaborate with others on the project. Share your repository publicly or privately, depending on your needs.Some popular Apache Spark projects on GitHub include:
Spark SQL: A library for structured data processing using SQL-like syntax. Spark MLlib: A machine learning library that provides simple interfaces for building and training various types of machine learning models. GraphFrames: A library for graph processing that integrates with the Spark API.These are just a few examples of what you can do with Apache Spark in Java and GitHub. The possibilities are endless, and I hope this helps you get started on your own Spark project!