How to run Java program in Spark?
How to run Java program in Spark?
Here's the answer:
Spark is a powerful unified analytics engine that can process large-scale data from various sources. It provides APIs for working with structured and unstructured data, including Hive and HBase.
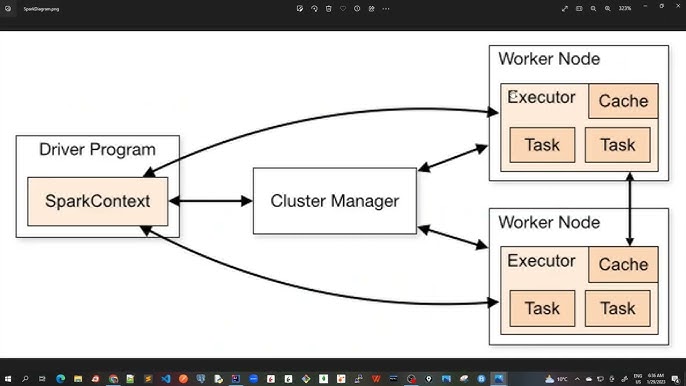
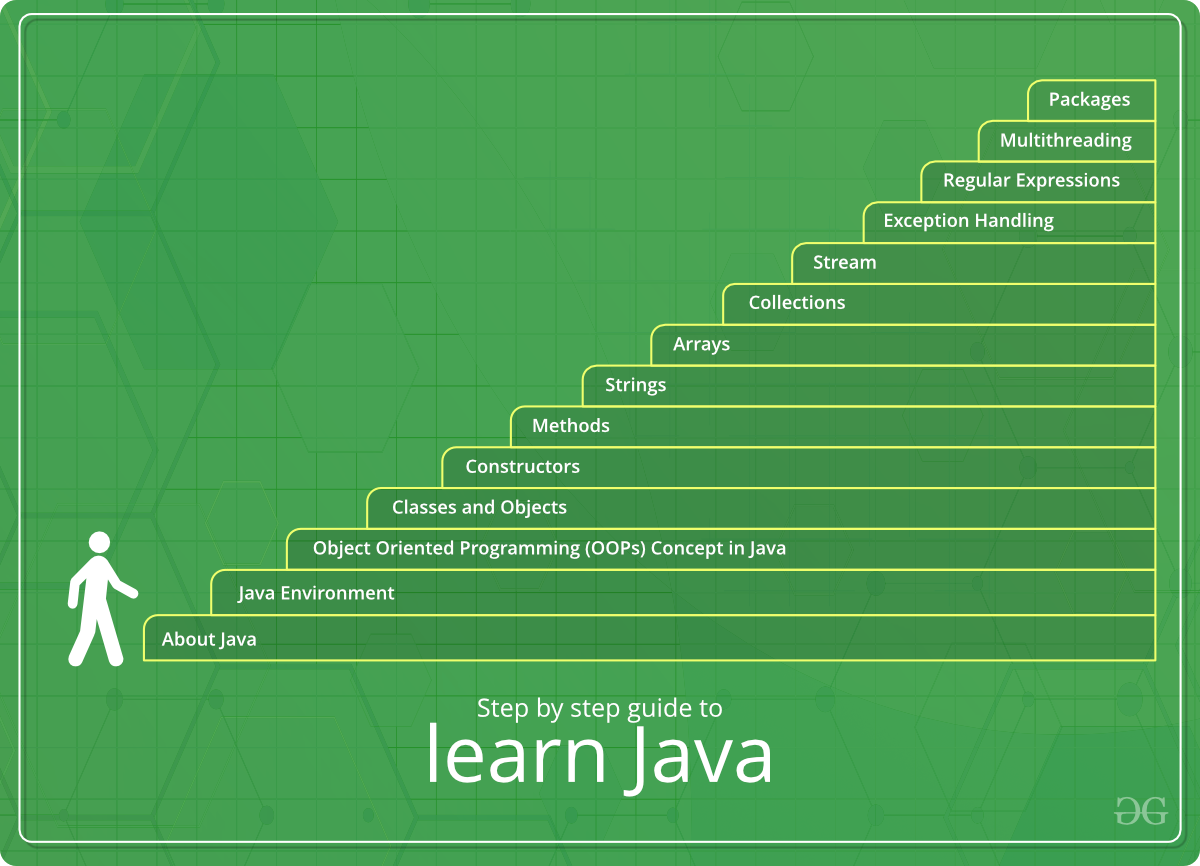
To run a Java program in Spark, you need to follow these steps:
Install Apache Spark: Download and install Apache Spark on your machine or use an existing installation if available. Import Spark Library: In your Java program, import the necessary Spark libraries by adding the following code:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
JavaSparkContext object to establish a connection with the Spark cluster or local mode:
SparkConf sparkConf = new SparkConf().setAppName("Your Application Name");
JavaSparkContext sc = JavaSparkContext.fromSparkConf(sparkConf);
// For CSV file
JavaRDD lines = sc.textFile("path_to_your_file.csv");
// For Hive table
Dataset df = sparkSession.read().format("hive").load("your_table_name");
Action or a Transformer. Actions perform computations on data, while Transformers transform the data:
// Example of an Action: Count the number of records in each partition
int count = sc.parallelize(your_data).map(x -> 1).reduce((a, b) -> a + b);
// Example of a Transformer: Convert uppercase text to lowercase
JavaRDD lowerCaseTexts = your_text_data.map(text -> text.toLowerCase());
sc object:
count = sc.parallelize(your_data).map(x -> 1).reduce((a, b) -> a + b);
System.out.println(count); // prints the result
// Write the result to a file
BufferedWriter writer = Files.newBufferedWriter("path_to_your_file.txt");
writer.write(String.valueOf(count));
writer.close();
Note that Java programs in Spark often involve writing custom functions using Scala, Python, or Java APIs. This example provides a basic overview of running Java programs within the Spark context. For more advanced topics and examples, you may need to learn about RDDs, DataFrames, DataSets, and Spark SQL.
Java apache spark w3schools example
I apologize for the confusion earlier! Here's a comprehensive guide on using Java and Apache Spark with W3Schools, along with examples.
Apache Spark is an open-source data processing engine that provides high-level APIs in Python, Java, and Scala to process large-scale datasets. In this example, we'll be using Java to create a Spark program that reads data from a text file, processes it, and writes the output back to another text file.
Before we start, make sure you have Apache Spark installed on your system and you have the necessary dependencies set up.
Step 1: Create a new Java project
Create a new Java project in your IDE (Integrated Development Environment) or use an existing one. Make sure it has the necessary dependencies for Apache Spark. You can add these dependencies manually or using Maven/Gradle build tools.
Here's what you need to add:
spark-core for core Spark functionality spark-sql for SQL support in Spark spark-avro for Avro support (optional)
Step 2: Import necessary libraries and create a SparkSession
In your Java class, import the necessary libraries and create a new SparkSession:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class W3SchoolsExample {
public static void main(String[] args) {
// Create a new SparkSession
SparkSession spark = SparkSession.builder()
.appName("W3Schools Example")
.getOrCreate();
// Create a JavaSparkContext
JavaSparkContext jsc = JavaSparkContext.fromSparkContext(spark.sparkContext());
}
}
Step 3: Read data from a text file
Use the spark.read() method to read data from a text file:
// Read data from a text file
Dataset df = spark.read().text("input.txt");
In this example, we're reading data from a file named "input.txt" in the current directory.
Step 4: Process the data
Now it's time to process the data. You can perform various operations such as filtering, mapping, or aggregating using Spark's high-level APIs:
// Filter out rows with less than 5 columns
df = df.filter(df.count() >= 5);
// Map each row to uppercase
df = df.map(row -> {
String[] cols = row.toString().split(",");
return new Row(cols);
});
// Aggregate the data by summing up a specific column
Map<String, Double> result = df.groupBy("column1")
.agg(sum("column2").as("sum"))
.collectAsMap();
Step 5: Write the output to another text file
Finally, use the spark.write() method to write the processed data back to a text file:
// Write the processed data to an output file
df.write().text("output.txt");
In this example, we're writing the output to a file named "output.txt" in the current directory.
Full code
Here's the full Java code for our W3Schools example:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class W3SchoolsExample {
public static void main(String[] args) {
// Create a new SparkSession
SparkSession spark = SparkSession.builder()
.appName("W3Schools Example")
.getOrCreate();
// Create a JavaSparkContext
JavaSparkContext jsc = JavaSparkContext.fromSparkContext(spark.sparkContext());
// Read data from a text file
Dataset df = spark.read().text("input.txt");
// Filter out rows with less than 5 columns
df = df.filter(df.count() >= 5);
// Map each row to uppercase
df = df.map(row -> {
String[] cols = row.toString().split(",");
return new Row(cols);
});
// Aggregate the data by summing up a specific column
Map<String, Double> result = df.groupBy("column1")
.agg(sum("column2").as("sum"))
.collectAsMap();
// Write the processed data to an output file
df.write().text("output.txt");
}
}
This code assumes you have a text file named "input.txt" with your data and another file named "output.txt" where you want to write the processed data. You can modify the code as per your requirements.
I hope this helps! Let me know if you have any questions or need further clarification.