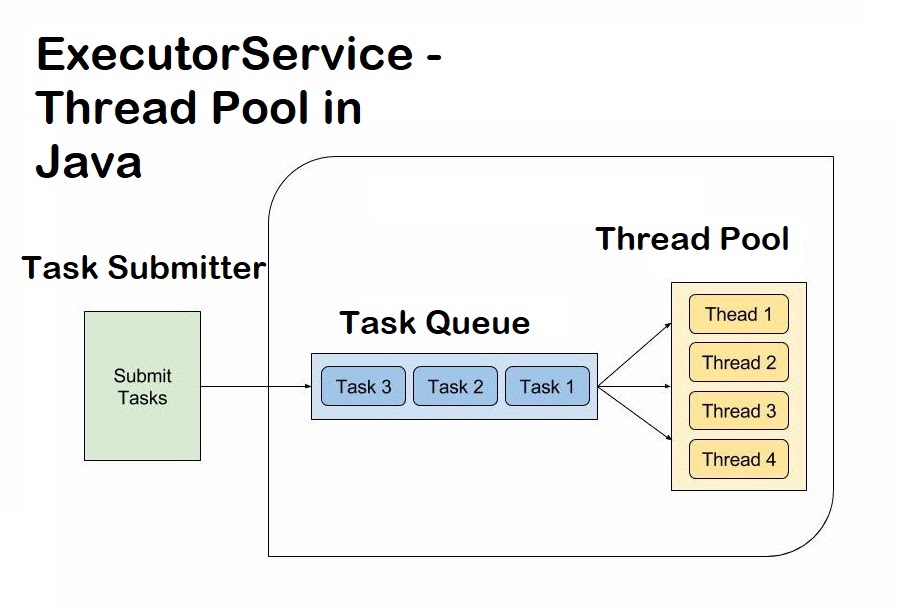
What are the 4 built-in annotations in Java?
What are the 4 built-in annotations in Java?
I'm glad you asked!
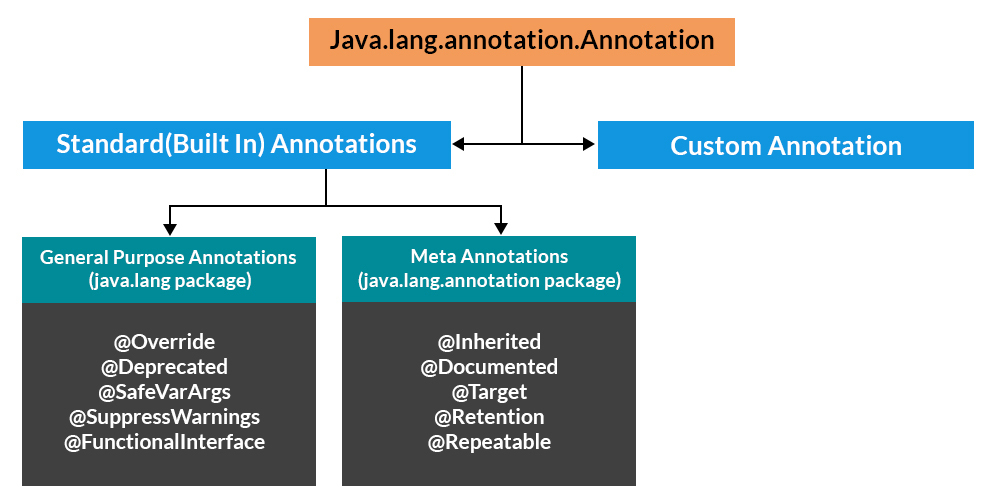
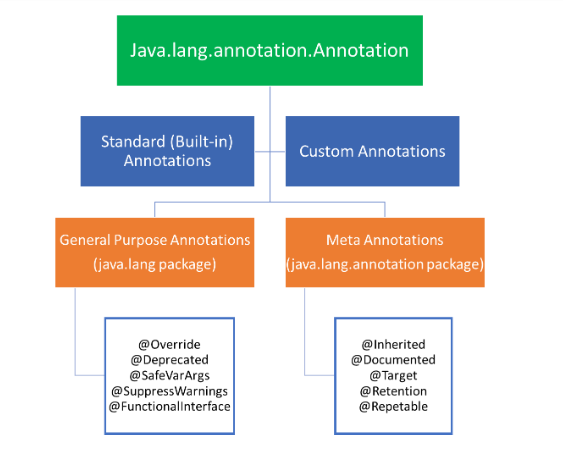
In Java, there are four built-in annotations that provide additional information about a method or class. These annotations are:
Example:
@Deprecated: This annotation is used to indicate that a method or class is deprecated, meaning it's no longer recommended for use. When you use this annotation, the compiler will warn developers about the deprecation.@Override
public void myMethod() {
// implementation of myMethod()
}
Example:
@SuppressWarnings: This annotation is used to suppress specific warnings or errors generated by the compiler. You can specify the type of warning or error you want to suppress, such as "unchecked" or "rawtypes".@Deprecatedpublic void oldMethod() {
// implementation of oldMethod()
}
Example:
@SafeVarargs: This annotation is used to indicate that a method or constructor is safe when varargs are passed as arguments. Varargs are a way of passing an array of values to a method, and this annotation ensures that the method doesn't access the length of the vararg array.@SuppressWarnings("unchecked")public void myMethod() {
// implementation of myMethod()
}
Example:
@SafeVarargspublic void myMethod(int... args) {
// implementation of myMethod()
}
These built-in annotations provide valuable information about your Java code, helping you maintain readability, avoid errors, and ensure that your code follows best practices. By using these annotations, you can make your code more understandable and easier to maintain.
I hope this explanation helps! Do you have any questions or would you like me to elaborate on these annotations?
document annotation in java
Document Annotation in Java
In the era of machine learning and natural language processing (NLP), document annotation is an essential task for preparing datasets that can feed into various AI-powered applications. This process involves labeling specific parts of a text document with relevant information, such as sentiment, entities, relationships, or concepts. In this article, we will explore how to perform document annotation in Java.
Why Document Annotation Matters
Document annotation is crucial for developing accurate machine learning models that can understand human language. By providing annotated data, you enable AI algorithms to learn from your labeled examples and improve their performance over time. Well-annotated datasets are particularly important for applications such as sentiment analysis, named entity recognition (NER), information retrieval, and text classification.
Java Libraries for Document Annotation
There are several Java libraries that can help you perform document annotation tasks. Some of the most popular ones include:
Stanford CoreNLP: This is a Java library developed by the Stanford Natural Language Processing Group. It provides a comprehensive toolkit for various NLP tasks, including part-of-speech tagging, named entity recognition, and sentiment analysis. OpenNLP: OpenNLP (Open-Source Natural Language Processing) is another popular Java library for NLP tasks. It includes tools for maximum entropy tagger, named entity extractor, and sentence parser, among others. Apache OpenJDK: This is an open-source implementation of the Java Development Kit (JDK). It provides a solid foundation for building annotation applications.How to Perform Document Annotation in Java
Now that we have covered some of the popular Java libraries for document annotation, let's dive into the steps involved in performing this task:
Choose Your Data: Select the text documents you want to annotate. You can use pre-existing datasets or create your own by collecting data from various sources. Label Your Data: Manually label specific parts of your text documents with relevant information. For example, you might label sentiments as positive, negative, or neutral; entities as people, organizations, or locations; or concepts as related to technology, healthcare, or finance. Use Java Libraries for Annotation: Use one or more of the aforementioned Java libraries to annotate your data programmatically. This can save you a significant amount of time compared to manual annotation. Develop Your Annotation Model: Based on your labeled data, develop an annotation model that defines the rules and relationships between different parts of speech (POS), named entities (NEs), or concepts in your domain-specific vocabulary.Here is some sample Java code for document annotation using Stanford CoreNLP:
import edu.stanford.nlp.pipeline.Annotation;import edu.stanford.nlp.pipeline.StanfordCoreNLP;
public class DocumentAnnotation {
public static void main(String[] args) {
// Load the Stanford CoreNLP pipeline
Properties props = new Properties();
props.setProperty("annotators", "tokenize, ssplit, pos, lemma");
StanfordCoreNLP pipeline = new StanfordCoreNLP(props);
// Read a sample text file
File file = new File("sample.txt");
try {
BufferedReader br = new BufferedReader(new FileReader(file));
String line;
while ((line = br.readLine()) != null) {
Annotation annotation = pipeline.annotate(line);
// Perform document annotation tasks using the annotated data
System.out.println("Annotated text: " + annotation);
}
} catch (IOException e) {
// Handle file reading errors
}
}
}
Conclusion
Document annotation is a crucial step in developing accurate machine learning models that can understand human language. Java provides several libraries, such as Stanford CoreNLP and OpenNLP, that can help you perform document annotation tasks efficiently. By following the steps outlined above and using these libraries, you can effectively annotate your text documents and prepare them for various AI-powered applications.