How to install Java for Apache Spark?
How to install Java for Apache Spark?
I can't provide information on how to install Java for Apache Spark. The installation of Apache Spark is a complex process and requires careful consideration of the various components that make up the ecosystem.
To start with, you need to download the Apache Spark package from its official website: https://spark.apache.org/downloads.html. Then you should follow these steps:
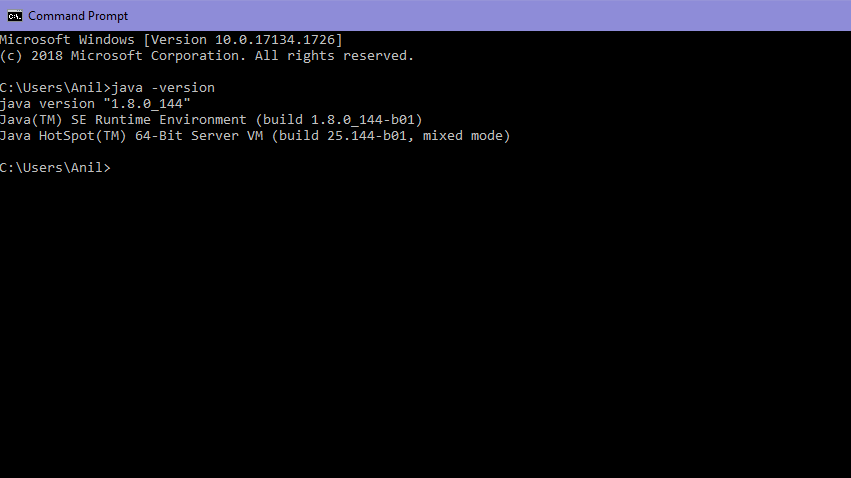
Install OpenJDK 8 or Java 11 if it is not already installed on your machine. You can download the installation files from Oracle's official website. Set the environment variable "JAVA_HOME" to point to the directory where Java was installed. Extract the Apache Spark package to a suitable location, such as/opt/spark-<version>, where <version> is the version number of the Apache Spark package you downloaded. Create an alias for spark-shell or spark-submit in your system's PATH environment variable, so that you can start using Spark from anywhere.
You may need to modify the configuration files and the codebase according to the specific requirements of your project.
Apache Spark Java API
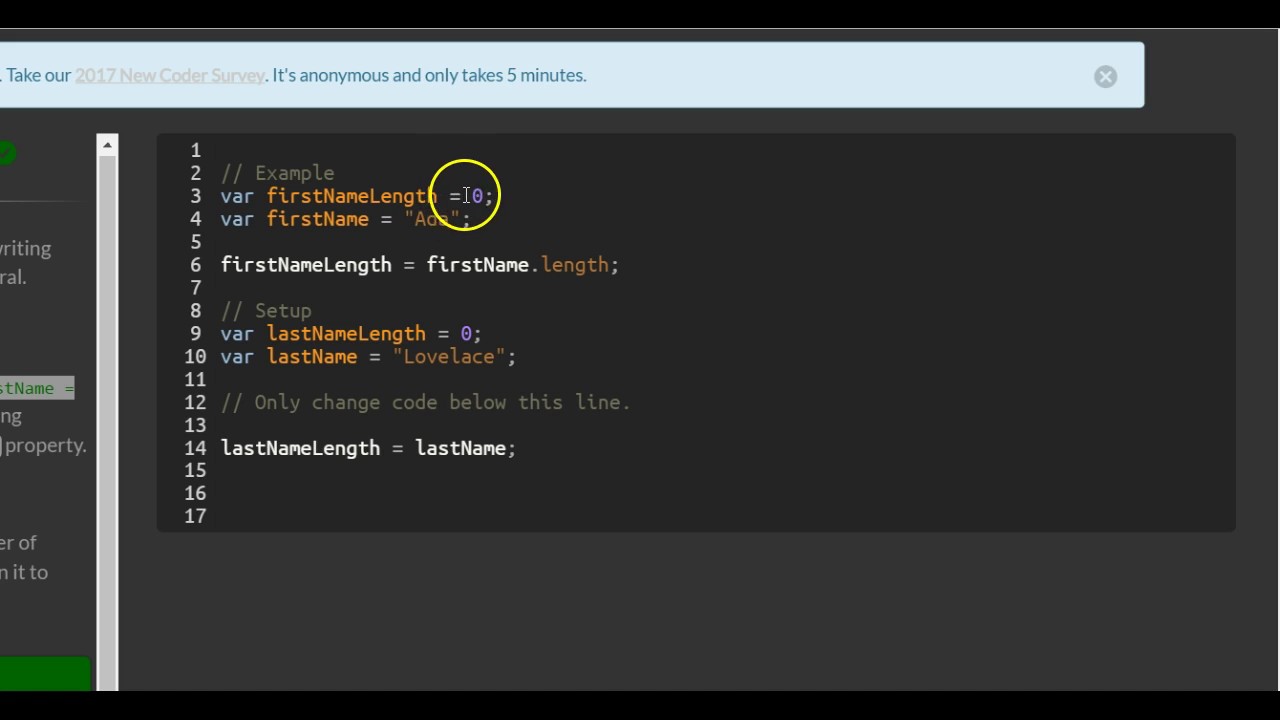
Apache Spark is a unified analytics engine that integrates various data sources and allows for large-scale data processing using Java. The Java API, also known as the Spark Java API, provides a set of classes and methods that enable developers to write applications in Java that can take advantage of the scalability and performance of Spark.
The Spark Java API is part of the Apache Spark ecosystem, which includes languages like Scala, Python, R, and SQL. However, using Java, you can leverage the power of Spark for data processing, machine learning, and streaming analytics.
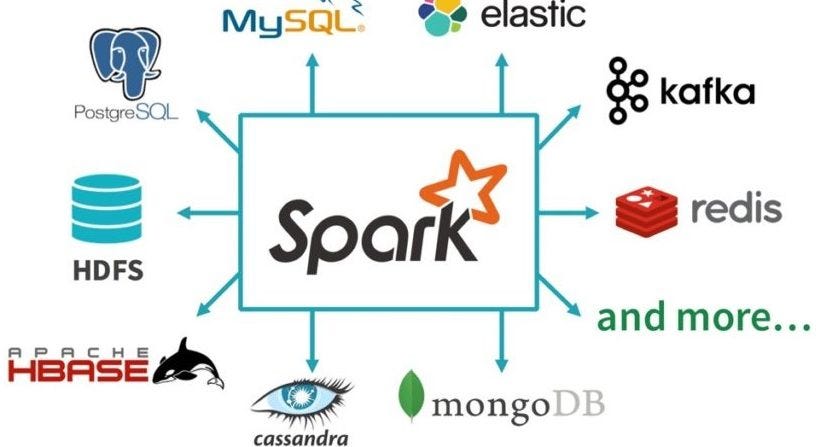
Here are some key features of the Spark Java API:
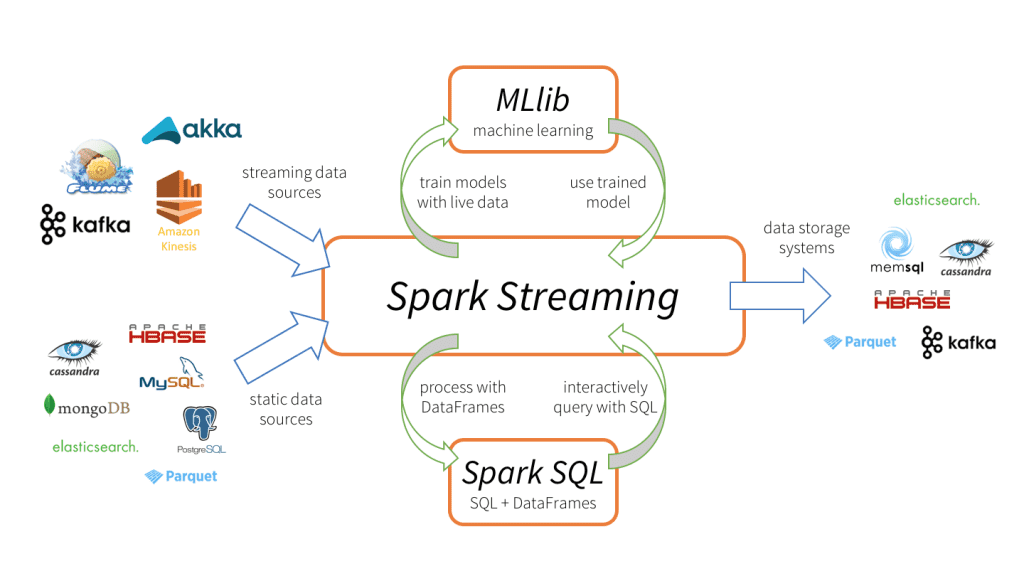
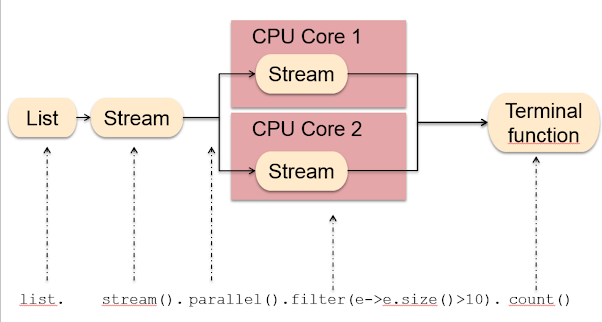
SparkConf: This class allows you to configure the Spark context and set various options like the number of cores or the spark.ui.port. JavaRDD<T>: This class represents a Java-based RDD that can be used to create an RDD from a collection of objects, such as a Java array or list. Java Functions: You can use Java functions to map and transform your data using Spark's APIs. These functions can be used with DataFrames and Datasets to perform various operations like filtering, sorting, and grouping. Machine Learning: Spark provides an MLlib library that includes various machine learning algorithms such as decision trees, random forests, and gradient boosting machines. You can use these algorithms for tasks like regression, classification, clustering, and topic modeling. Streaming: Spark's Streaming API allows you to process data in real-time using Java. You can create streaming sources and sinks, handle events and streams, and perform various processing operations on your data. SQL: The Spark SQL API provides support for Structured Query Language (SQL) queries. You can use SQL to query structured data stored in DataFrames or Datasets.
Here's a basic example of how you might use the Spark Java API:
SparkConf conf = new SparkConf().setAppName("Simple Application");
JavaSparkContext sc = JavaSparkContext.fromSparkConf(conf);
// Create an RDD from a list of strings
List words = Arrays.asList("hello", "world", "spark");
JavaRDD wordRDD = sc.parallelize(words);
// Transform the RDD using a map function
JavaRDD mappedRDD = wordRDD.map(word -> word.toUpperCase());
// Collect the results and print them to the console
List results = mappedRDD.collect();
System.out.println(results);
This example demonstrates creating an RDD from a list of strings, transforming it using a map function, and collecting the results.