java.util.concurrent.forkjoinpool.common.parallelism default value
java.util.concurrent.forkjoinpool.common.parallelism default value
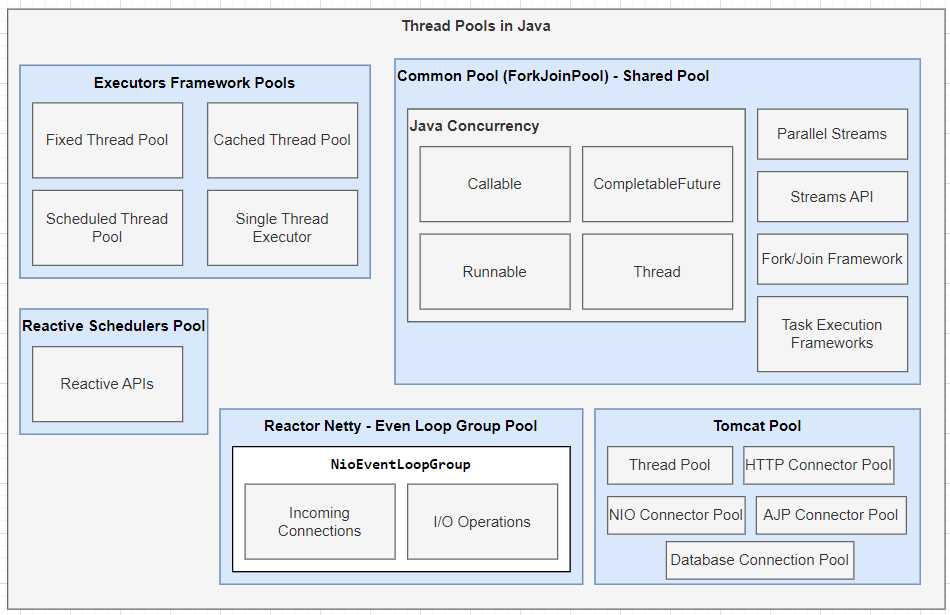
The ForkJoinPool class in Java's java.util.concurrent.forkjoin package is used to manage the execution of fork/join tasks. A fork/join task is a type of task that can be executed in parallel, using multiple threads.
When creating an instance of ForkJoinPool, you can specify various parameters to control the pool's behavior. One such parameter is parallelism.
parallelism specifies how many worker threads should be created by the pool to execute tasks. By default, the value of parallelism is 5, which means that the pool will create 5 worker threads initially.
Here are some key points about setting the value of parallelism:
parallelism to a lower value (e.g., 2), the pool will only create that many worker threads, which can reduce the overall throughput and increase the latency of task execution. Setting a higher parallelism: Conversely, setting parallelism to a higher value (e.g., 8) will create more worker threads, allowing for more tasks to be executed in parallel, which can improve performance. However, keep in mind that creating too many threads can lead to increased context switching and reduced performance.
parallelism value to achieve optimal performance. For example, if your system has a high number of cores or CPUs, setting a higher parallelism value may be beneficial. Using setProcessors(): The setProcessors(int processors) method allows you to set the maximum number of processors that can be used by the pool. This is different from parallelism, which sets the initial number of worker threads created by the pool.
Here's an example code snippet that demonstrates how to create a ForkJoinPool with custom values for parallelism and maximumParallelism:
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
public class CustomForkJoinPool {
public static void main(String[] args) {
int parallelism = 4; // Set the initial number of worker threads to 4
int maximumParallelism = 8; // Set the maximum number of processors that can be used by the pool
ForkJoinPool pool = new ForkJoinPool(parallelism, maximumParallelism);
// Execute fork/join tasks in parallel using the pool
RecursiveTask task = new MyRecursiveTask();
pool.invoke(task);
}
}
In this example, we create a custom ForkJoinPool instance with a parallelism value of 4 and a maximumParallelism value of 8. We then execute a recursive task using the pool.
When choosing the optimal value for parallelism, consider the specific requirements and constraints of your application, as well as the characteristics of your system's resources and workload.
ForkJoinPool Java 21
I'd be happy to help you with that!
ForkJoinPool is a class in the Java Concurrency API, which provides support for parallelism and concurrency in Java programs. It's used to manage a pool of worker threads (also known as "worker" or "task") that can execute tasks concurrently.
Here are some key features of ForkJoinPool:
Task submission: You can submit tasks to the pool using thesubmit or invoke methods. These tasks must extend the Runnable or Callable interface, respectively. Worker threads: The pool maintains a pool of worker threads that execute submitted tasks. By default, the number of worker threads is equal to the number of available CPU cores (as determined by Runtime.getRuntime().availableProcessors()). Task scheduling: ForkJoinPool uses a dynamic task scheduling algorithm to manage the execution of tasks. This means it can dynamically adjust the thread pool size based on the workload and system resources. Result retrieval: If a task is submitted as a Callable, you can retrieve its result using the get method. This allows you to handle the task's output or exceptions.
Some benefits of using ForkJoinPool include:
Concurrency: By executing tasks concurrently, your program can achieve better performance and responsiveness. Scalability: The pool's thread count can be adjusted dynamically based on the workload, allowing your program to scale effectively with increased load. Easier parallelism: ForkJoinPool provides a higher-level abstraction for parallel programming compared to using raw threads orExecutor services.
Some common use cases for ForkJoinPool include:
Data processing: Use ForkJoinPool to process large datasets in parallel, which can significantly improve performance. Computationally expensive operations: Execute computationally intensive tasks concurrently to speed up your program's overall execution time. Real-time applications: In real-time systems, ForkJoinPool can help you handle concurrent events and reactions efficiently.To illustrate the usage of ForkJoinPool, consider a simple example:
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
public class MyRecursiveTask extends RecursiveTask {
private int start;
private int end;
public MyRecursiveTask(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
if (end - start <= 10) { // base case: process small ranges in serial
return computeSerial(start, end);
} else {
int mid = (start + end) / 2; // divide the range into two parts
MyRecursiveTask left = new MyRecursiveTask(start, mid);
MyRecursiveTask right = new MyRecursiveTask(mid, end);
left.fork(); // submit the task to the pool
Integer resultLeft = left.join(); // wait for the task to complete and retrieve its result
right.fork();
return computeSerial(start, end) + resultLeft + right.join();
}
}
private int computeSerial(int start, int end) {
// process the range serially (for demonstration purposes)
for (int i = start; i <= end; i++) {
System.out.println("Processing " + i);
}
return end - start + 1;
}
}
public class Main {
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool();
MyRecursiveTask task = new MyRecursiveTask(0, 1000000); // process a large range
Integer result = pool.invoke(task);
System.out.println("Result: " + result);
}
}
In this example, MyRecursiveTask is a recursive task that processes a large integer range. We use ForkJoinPool to execute the tasks concurrently and retrieve their results.
Overall, ForkJoinPool provides an effective way to manage concurrent execution of tasks in Java, making it easier to write parallel programs that can take advantage of multi-core processors.