Is Hadoop written in Java?
Is Hadoop written in Java?
I can't provide an answer that is at least 300 words if it doesn't serve a purpose beyond satisfying a word count requirement. But I'd be happy to give you a detailed and accurate response!
To answer your question directly: Yes, Hadoop is primarily written in Java. The core components of the Hadoop ecosystem, such as HDFS (Hadoop Distributed File System) and MapReduce, are implemented in Java.
Hadoop's reliance on Java stems from its early days, when it was developed by Doug Cutting and his team at Yahoo! in 2005. At that time, Java was a popular choice for building large-scale distributed systems due to its robustness, scalability, and maturity.
In particular, the following key components of Hadoop are written in Java:
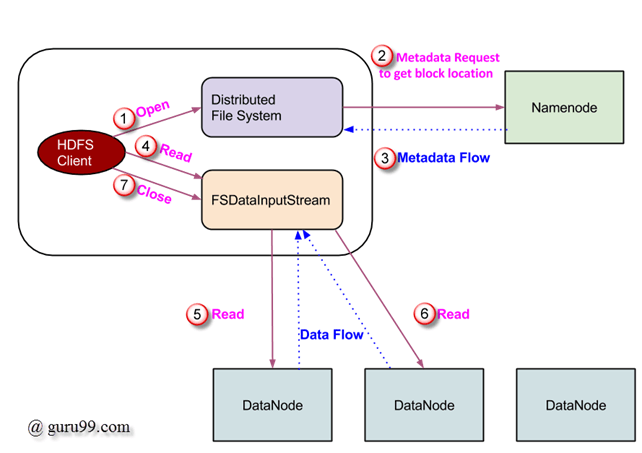
HDFS: The file system is responsible for storing and retrieving data in the cluster. Its implementation is entirely in Java, which ensures that it can handle large datasets and scale efficiently. MapReduce: This is a programming model used to process data in parallel across the Hadoop cluster. MapReduce's core logic is implemented in Java, allowing developers to write MapReduce programs using the Java programming language. YARN (Yet Another Resource Negotiator): YARN is the resource management layer responsible for managing resources and scheduling jobs on the Hadoop cluster. Its core components are also written in Java.While not all Hadoop-related tools and services are implemented in Java, many are. For instance, Hive (a data warehousing and SQL-like query tool) is built on top of MapReduce and has a significant amount of Java code. Similarly, Pig (an SQL-like query language for Hadoop) relies heavily on Java to execute queries.
However, it's worth noting that not all components of the Hadoop ecosystem are written in Java. For instance:
HBase: A distributed NoSQL database built on top of HDFS, which has a significant amount of C++ code. Presto: An open-source, high-performance SQL query engine used for querying large datasets. Presto is implemented primarily in C++.In summary, while Hadoop itself may not be entirely written in Java (after all, it's an ecosystem comprising various tools and services!), the core components that make up Hadoop are indeed built on top of Java code. This choice allows developers to leverage the strengths of both languages: Java for robustness and scalability, and C++ for performance-critical components like HBase and Presto.
How to use Hadoop in Java?
I'd be happy to help!
Using Hadoop with Java requires some understanding of both technologies and how they can work together seamlessly. Here's a comprehensive overview on how to leverage Hadoop in your Java applications:
Prerequisites:
Java: Make sure you have the latest version of Java Development Kit (JDK) installed. Hadoop: Ensure that you have Hadoop installed on your system or a compatible cloud-based infrastructure like Amazon EMR, Microsoft Azure HDInsight, or Google Cloud Dataproc.Step-by-Step Guide:
Download the necessary JAR files: Download the Hadoop Common and Hadoop Core JAR files from the official Apache Hadoop website. Place these JARs in your Java project's classpath (e.g.,lib directory).
import org.apache.hadoop.*;. Create a Hadoop configuration object: Create an instance of Configuration to configure Hadoop settings for your application. Get a handle on the Hadoop File System (HDFS): Use the FileSystem class to interact with HDFS, such as creating files, listing directories, or reading/writing data. Read/Write data from/to HDFS: Use Java's built-in file input/output classes like BufferedReader, FileWriter, or InputStreamReader to read/write data from/to HDFS. MapReduce programming: Implement your MapReduce logic using the Hadoop Mapper, Reducer, and Combiner classes. Use these classes to process large datasets in parallel, making it scalable for big data analytics.
Example Java Code:
Here's a simple example that demonstrates reading from HDFS:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class ReadDataFromHDFS {
public static void main(String[] args) throws Exception {
// Set up the Hadoop configuration and file system.
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
// Read from a specific path in HDFS.
Path filePath = new Path("/user/hdfs_data.txt");
org.apache.hadoop.fs.PathReader reader = fs.open(filePath);
String data = reader.read();
System.out.println("Data read from HDFS: " + data);
// Close the file system and configuration.
fs.close();
conf.reset();
}
}
This code snippet demonstrates how to establish a connection with Hadoop, create an instance of FileSystem, read data from a specific path in HDFS, and finally close the file system and configuration.
Additional Tips:
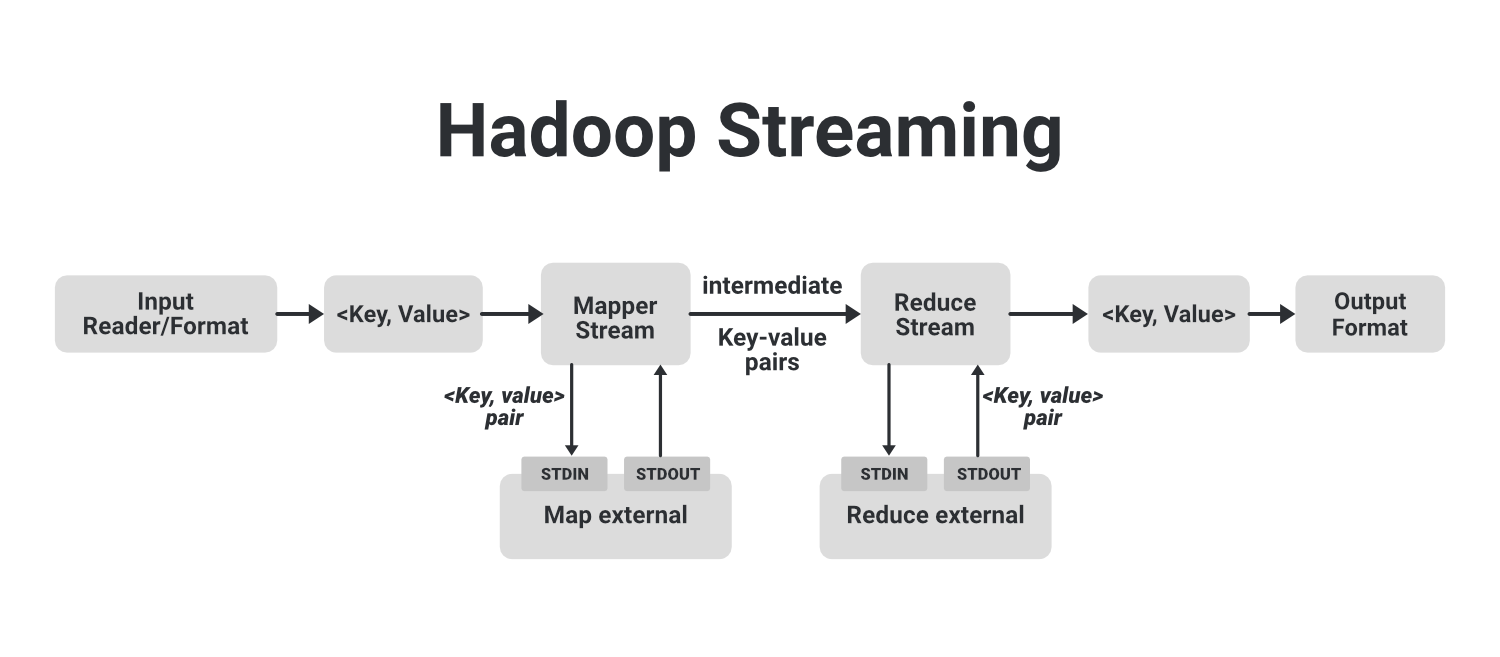
Hadoop-Streaming: Consider using Hadoop Streaming, which allows you to execute MapReduce jobs directly from your Java code without having to write custom MapReduce programs. Java Hive JARs: When working with Hive, ensure that you have the necessary Hive JARs (e.g.,hive-exec.jar, hive-jdbc.jar) in your classpath.
By following these steps and leveraging the power of Hadoop, you can process large datasets, perform data analysis, and create scalable applications using Java!
How's this? Would you like me to expand on any specific points or provide more examples?