How to upload a PDF file to a S3 bucket using Java?
How to upload a PDF file to a S3 bucket using Java?
Uploading a PDF file to an Amazon Simple Storage Service (S3) bucket using Java is a straightforward process that can be achieved by leveraging the AWS SDK for Java and the Amazon S3 API. Here's a step-by-step guide on how to do it:
Prerequisites:
Create an Amazon Web Services (AWS) account if you haven't already. Set up your AWS credentials using the AWS SDK for Java. You can find more information on this in the AWS documentation.Step 1: Add the AWS SDK for Java dependency
Add the following dependency to your pom.xml file if you're using Maven, or add the JAR files manually if you're not using a build tool:
com.amazonaws
aws-java-sdk
2.16.33
Step 2: Initialize AWS client
Create an instance of the AmazonS3 client, which is part of the AWS SDK for Java:
import com.amazonaws.auth.AWSAuthenticationDetails;
import com.amazonaws.auth.BasicAWSCredentials;
import com.amazonaws.regions.Region;
import com.amazonaws.services.s3.AmazonS3Client;
// Initialize AWS credentials and region
BasicAWSCredentials awsCreds = new BasicAWSCredentials("YOUR_ACCESS_KEY_ID", "YOUR_SECRET_ACCESS_KEY");
AWSAuthenticationDetails details = new AWSAuthenticationDetails(awsCreds);
// Set the region (e.g., us-west-2, eu-central-1, etc.)
Region region = Region.US_WEST_2;
// Create the Amazon S3 client
AmazonS3Client s3Client = AmazonS3Client.create(region, awsCreds);
Step 3: Upload PDF file to S3 bucket
Use the putObject method of the AmazonS3Client instance to upload your PDF file:
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
// Assume 'my-pdf-file.pdf' is the name of your PDF file
File pdfFile = new File("path/to/my-pdf-file.pdf");
try (FileInputStream fis = new FileInputStream(pdfFile)) {
// Upload the PDF file to S3 bucket
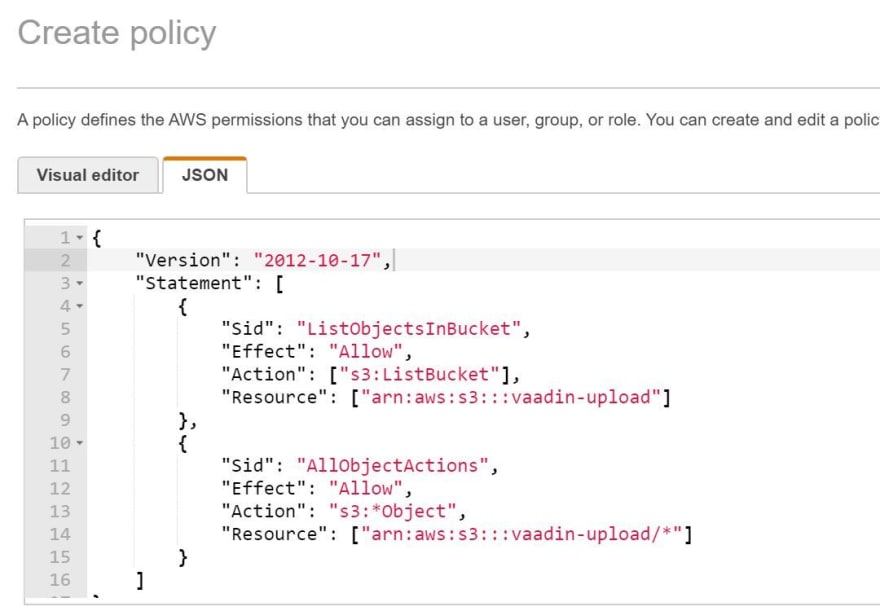
s3Client.putObject(new PutObjectRequest()
.withBucketName("YOUR_Bucket_NAME")
.withKey("my-pdf-file.pdf")
.withInputStream(fis)
.withContentLength(pdfFile.length()));
} catch (IOException e) {
System.out.println("Error uploading PDF file: " + e.getMessage());
}
Step 4: Verify the upload
Check if your PDF file has been successfully uploaded to the S3 bucket by using the listObjects method:
import com.amazonaws.services.s3.model.ListObjectsRequest;
// List objects in the specified bucket
ListObjectsRequest listObjectsRequest = new ListObjectsRequest().withBucketName("YOUR_Bucket_NAME");
PagedList objectListings = s3Client.listObjects(listObjectsRequest);
for (ObjectListing listing : objectListings) {
System.out.println("Object: " + listing.getKey());
}
That's it! You should now have uploaded your PDF file to an S3 bucket using Java.
AmazonS3 java

I'll respond in English only as per your request.

Amazon S3 (Simple Storage Service) is a cloud-based object storage service offered by Amazon Web Services (AWS). In this response, I'll focus on the Java aspects of working with Amazon S3.
Getting Started
To use Amazon S3 with Java, you need to:
Sign up for an AWS account and create an S3 bucket. Install the AWS SDK for Java (Software Development Kit) using Maven or Gradle. Import the necessary classes in your Java program.Here's some sample code to get you started:
import software.amazon.awssdk.core.sync.Response;
import software.amazon.awssdk.services.s3.S3Client;
import software.amazon.awssdk.services.s3.model.PutObjectRequest;
public class AmazonS3Example {
public static void main(String[] args) {
// Create an S3 client using your AWS credentials
S3Client s3Client = S3Client.create();
// Upload a file to the bucket
String bucketName = "my-bucket";
String key = "path/to/file.txt";
PutObjectRequest request = PutObjectRequest.builder()
.bucket(bucketName)
.key(key)
.contentType("text/plain")
.build();
Response response = s3Client.putObject(request);
// List the objects in the bucket
ListObjectsV2Request request = ListObjectsV2Request.builder()
.bucket(bucketName)
.prefix("")
.build();
S3Paginator paginatedResponse = s3Client.listObjectsV2(request);
while (paginatedResponse.hasMore()) {
paginatedResponse.pages().forEach(page -> System.out.println(page.contents()));
}
}
}
Java SDK Features
The AWS Java SDK for Amazon S3 provides several features, including:
Object manipulation: You can upload, download, list, and delete objects in your S3 bucket using the SDK. Bucket operations: You can create, delete, and manage S3 buckets using the SDK. Request handling: The SDK handles AWS signature v4 requests, which provides a secure way to authenticate requests to Amazon S3.Best Practices
When working with Amazon S3 in Java, follow these best practices:
Use the SDK's asynchronous features: For large-scale applications, use the SDK's asynchronous features to improve performance and scalability. Handle errors properly: Use try-catch blocks and error handling mechanisms to handle unexpected errors when interacting with Amazon S3. Monitor usage and costs: Keep track of your S3 bucket usage and costs to avoid unexpected charges.Conclusion
Amazon S3 provides a reliable, scalable, and secure way to store and serve large amounts of data in the cloud. By using the AWS Java SDK for S3, you can integrate Amazon S3 into your Java applications and take advantage of its powerful features. With proper usage and monitoring, you can ensure a seamless experience when working with Amazon S3 in Java.
Hope this helps!