How does HashMap implemented in Java?
How does HashMap implemented in Java?
HashMap is a fundamental data structure in the Java programming language that provides an efficient way to store and retrieve key-value pairs. The implementation of HashMap in Java is based on the concept of hashing, which maps keys to indices of an array.
How Does HashMap Work?
A HashMap in Java consists of a collection of key-value pairs, where each pair is represented by a key and its corresponding value. The key is used as an index into a backing array, which stores the actual values. Here's a high-level overview of how HashMap works:
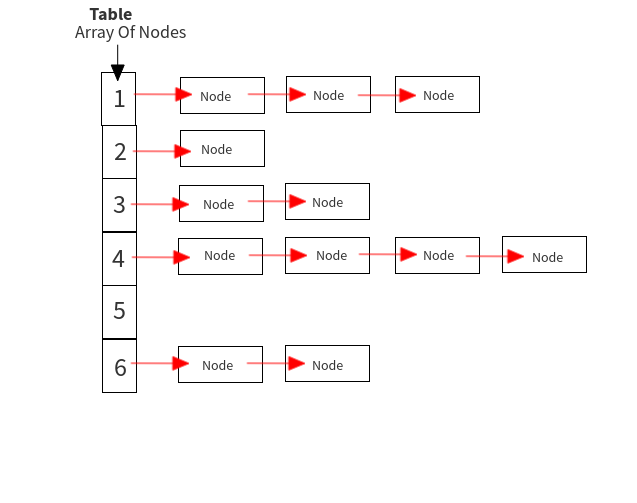
Hashing: When you put a new key-value pair into the map using theput() method, the HashMap calculates the hash code for the key using its own hashing algorithm. Index calculation: The hash code is then used to calculate the index into the backing array where the value should be stored. This is done by performing some arithmetic operations on the hash code and taking the result modulo the length of the backing array. Collision resolution: If multiple keys have the same calculated index, this is called a collision. To resolve collisions, HashMap uses a technique called chaining, which involves storing collided entries in a linked list.
HashMap Implementation
The HashMap class in Java is implemented as an abstract data type that provides methods for adding, removing, and retrieving key-value pairs. The implementation is based on the following components:
Backing array: A dynamic array of objects (Entry[]) where each element represents a key-value pair. Entry object: An internal class that represents a single key-value pair. It contains the key, value, and next reference for chaining collisions. Hash function: An algorithm used to calculate the hash code for a given key.
The implementation of HashMap in Java involves several optimizations and tweaks to ensure efficiency and performance:
Initial capacity: The initial size of the backing array is set to 16 (2^4). This allows for efficient storage and retrieval of entries. Load factor: The load factor determines when the backing array needs to be resized. A load factor of 0.75 means that if the map contains more than 75% filled slots, it will automatically resize its backing array. Chaining: As mentioned earlier, chaining is used to resolve collisions. HashMap uses a linked list to store collided entries.Performance Considerations
To achieve optimal performance, the Java implementation of HashMap has several performance considerations:
Hash code calculation: The hash code calculation is optimized for speed and accuracy. Collision resolution: Chaining is used to minimize the impact of collisions on performance. Resizing: The backing array is resized efficiently using a combination of arithmetic and bitwise operations.In summary, the HashMap implementation in Java provides an efficient way to store and retrieve key-value pairs by leveraging hashing, collision resolution through chaining, and dynamic resizing. The optimizations and tweaks made to the implementation ensure that it remains performant and scalable for a wide range of applications.
How to implement cache in java using hashmap without

Implementing a cache in Java using a HashMap without third-party libraries involves creating a custom cache class that leverages the benefits of Hash Maps to store and retrieve cached data efficiently.
Here's an example implementation:
import java.util.HashMap;
import java.util.Map;
public class Cache<K, V> {
private Map<K, V> cacheMap = new HashMap<>();
private int cacheSize; // maximum size of the cache
public Cache(int capacity) {
cacheSize = capacity;
}
public void put(K key, V value) {
if (cacheMap.size() >= cacheSize) {
// evict the least recently used item from the cache
K evictKey = getEvictionKey();
cacheMap.remove(evictKey);
}
cacheMap.put(key, value);
}
public V get(K key) {
return cacheMap.getOrDefault(key, null); // return null if not found in cache
}
private K getEvictionKey() {
// implement an eviction policy (e.g., LRU, FIFO)
// for this example, we'll use a simple FIFO approach
K[] keys = (K[]) cacheMap.keySet().toArray(new K[0]);
return keys[0]; // evict the first item in the list
}
public void clear() {
cacheMap.clear();
}
}
In this implementation:
We define a generic classCache with type parameters K and V, representing the key-value pairs stored in the cache. The constructor initializes the cache size, which determines how many items can be stored in the cache at any given time. The put method adds an item to the cache. If the cache is already full (i.e., its size equals the capacity), it evicts the least recently used (LRU) or first-in-first-out (FIFO) item from the cache by removing it from the map and then puts the new item into the map. The get method retrieves an item from the cache. If the item is not found in the cache, it returns null. The clear method clears the entire cache.
This implementation demonstrates a basic LRU eviction policy. You can modify or extend this code to implement more sophisticated policies (e.g., LFU, Random) depending on your specific use case and performance requirements.
Here's how you could use this Cache class:
public class Example {
public static void main(String[] args) {
Cache<String, Integer> cache = new Cache<>(10); // 10-slot cache
cache.put("key1", 10);
cache.put("key2", 20);
cache.put("key3", 30);
System.out.println(cache.get("key1")); // prints 10
System.out.println(cache.get("key4")); // prints null (not found in cache)
cache.clear(); // clears the entire cache
cache.put("newKey", 40); // adds a new item to the cleared cache
}
}
This example demonstrates basic usage of the Cache class. You can modify it to fit your specific requirements and test its performance and functionality.
Remember that this is just a simplified implementation, and you should consider factors like concurrency, thread safety, and cache expiration when designing a production-ready cache system.