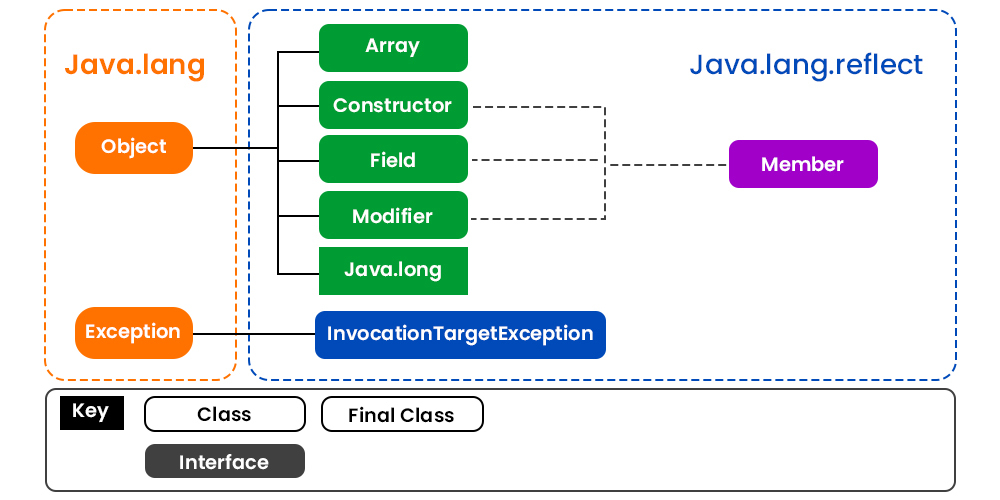
Is Java good for Spark?
Is Java good for Spark?
I'd be happy to help!
Java is indeed a great choice when it comes to building applications with Apache Spark. In fact, Java is one of the most popular programming languages used with Spark, and there are several reasons why.
Firstly, Java is a mature and widely adopted language that has been around for decades. Its ecosystem is vast and well-established, making it easier to find libraries, tools, and talent to work on large-scale data processing projects like those involving Spark.
Secondly, Java's object-oriented nature makes it an excellent fit for building scalable applications that can handle massive datasets. The language's support for multi-threading, concurrency, and garbage collection also helps optimize performance when working with big data.
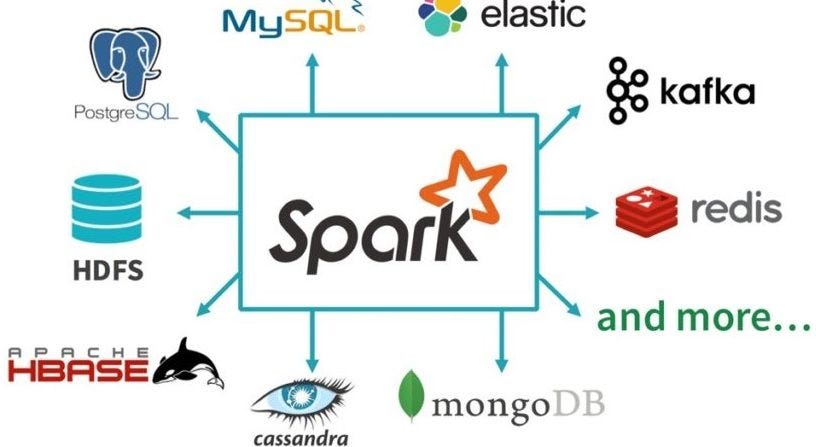
Thirdly, since Apache Spark is built on top of the Hadoop ecosystem, using Java as your programming language of choice allows you to seamlessly integrate with other popular Big Data tools like Hive, Pig, and Cassandra. This integration enables you to leverage the strengths of each technology to build a comprehensive Big Data processing pipeline.
Fourthly, Java's popularity among enterprise developers means that there are many established frameworks and libraries available for tasks such as data integration, visualization, and reporting. This makes it easier to incorporate Spark into your existing development workflow, leveraging the strengths of both worlds.
Lastly, Scala (a language with strong ties to Java) is another popular choice when working with Spark. Scala's concise syntax and support for functional programming make it an excellent fit for building data processing applications that can leverage Spark's scalability and parallel processing capabilities.
In conclusion, Java is indeed a fantastic choice for building applications with Apache Spark. Its mature ecosystem, object-oriented nature, scalability, integration possibilities, and familiarity among enterprise developers all contribute to making Java a popular and effective language for large-scale data processing projects like those involving Spark.
How to deploy Spark Java application?
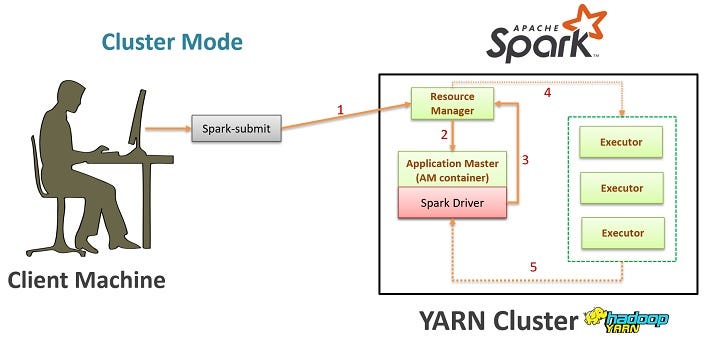
Deploying a Spark Java application involves several steps that ensure the app is properly packaged and run in a production environment. Here's a step-by-step guide to help you achieve this:
Step 1: Create a JAR file
First, create a JAR file (Java Archive) for your Spark Java application using Maven or Gradle. This will bundle all necessary libraries, classes, and dependencies into a single executable package.
To do this in Maven, add the following plugin to your pom.xml file:
org.apache.maven.plugins
maven-compiler-plugin
3.8.0
1.8
1.8
jar
Then, run the command mvn package to create a JAR file named <your-app-name>.jar.
Step 2: Configure your Spark application
Before deployment, make sure you've properly configured your Spark application. This includes setting up logging, configuring Spark parameters (e.g., spark.app.name, spark.driver.memory, etc.), and adding any necessary dependencies.
You can do this by creating a SparkApplication class that extends JavaSparkApplication. In this class, define the main method where you create and configure your Spark session:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkApplication;
public class YourSparkApp extends JavaSparkApplication {
public static void main(String[] args) {
// Configure Spark
SparkConf conf = new SparkConf()
.setAppName("Your Spark App")
.setMaster("local[4]") // Change this to your cluster setup
.setExecutorMemory("1g");
JavaSparkApplication.run(YourSparkApp.class, args);
}
}
Step 3: Package the application with dependencies
Use a tool like Apache Maven Assembly or Gradle's Shade plugin to package your Spark application along with its dependencies. This ensures that all necessary libraries and JAR files are included in the deployment.
In Maven, add the assembly plugin to your pom.xml file:
org.apache.maven.plugins
maven-assembly-plugin
3.1.0
package
single
module
module
Then, run the command mvn assembly:package to create a JAR file that includes your Spark application and its dependencies.
Step 4: Deploy the application
Once you have a packaged JAR file, you can deploy it to various environments, such as:
Local environment: Run the JAR file directly usingjava -jar your-app.jar. Docker container: Create a Docker image with your Spark application and its dependencies. Then, use the docker run command to launch the container. Cloud platform: Deploy your application to cloud platforms like AWS EMR, Google Cloud Dataproc, or Azure HDInsight.
For example, you can deploy your Spark application to an AWS EMR cluster using the spark-submit command:
aws emr add-instance --cluster-id --instance-type "m4.10xlarge"
aws emr run-job-flow --name "" --jar-file your-app.jar
Step 5: Monitor and maintain
Finally, monitor your application's performance, logs, and resource utilization to ensure it runs smoothly in production. Set up metrics tracking (e.g., Prometheus, Grafana) and use tools like Spark UI or Apache Zeppelin to inspect job progress and error messages.
By following these steps, you can successfully deploy your Spark Java application to various environments and maintain a scalable and efficient data processing pipeline.