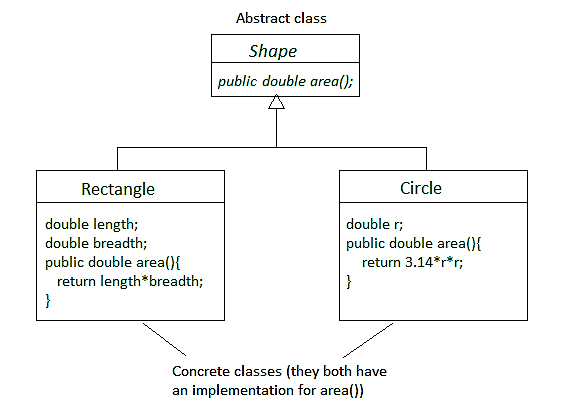
OpenNLP Java example
OpenNLP Java example
Here's an example of using OpenNLP for part-of-speech (POS) tagging and named entity recognition (NER) in Java:
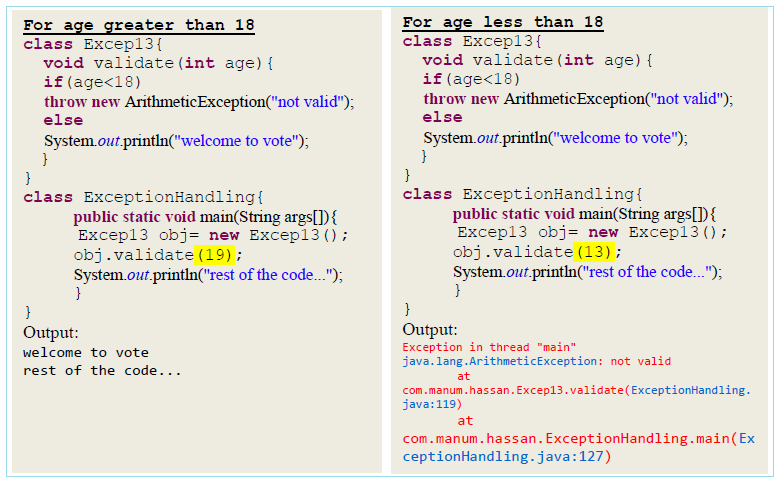
POSTagger Example
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
public class POSTaggerExample {
public static void main(String[] args) throws Exception {
// Load the POS model
String posModelFile = "en-pos-maxent.bin";
POSModel posModel = new POSModel(posModelFile);
// Create a POS tagger
POSTaggerME posTagger = new POSTaggerME(posModel);
// Text to be tagged
String text = "The quick brown fox jumps over the lazy dog.";
// Tag the text
String[] tokens = text.split(" ");
int[] tokenPos = new int[tokens.length];

for (int i = 0; i < tokens.length; i++) {
tokenPos[i] = posTagger.tag(tokens[i]);
}
// Print the tagged text
for (int i = 0; i < tokens.length; i++) {
System.out.println(tokens[i] + "/" + tokenPos[i]);
}
}
}
This code loads a POS model for English, creates a POS tagger, and tags a sample sentence. The output will be something like:
The / DT
quick / JJ
brown / JJ
fox / NN
jumps / VBZ
over / IN
the / DT
lazy / JJ
dog / NN
. / .
This shows the POS tag for each word in the sentence.
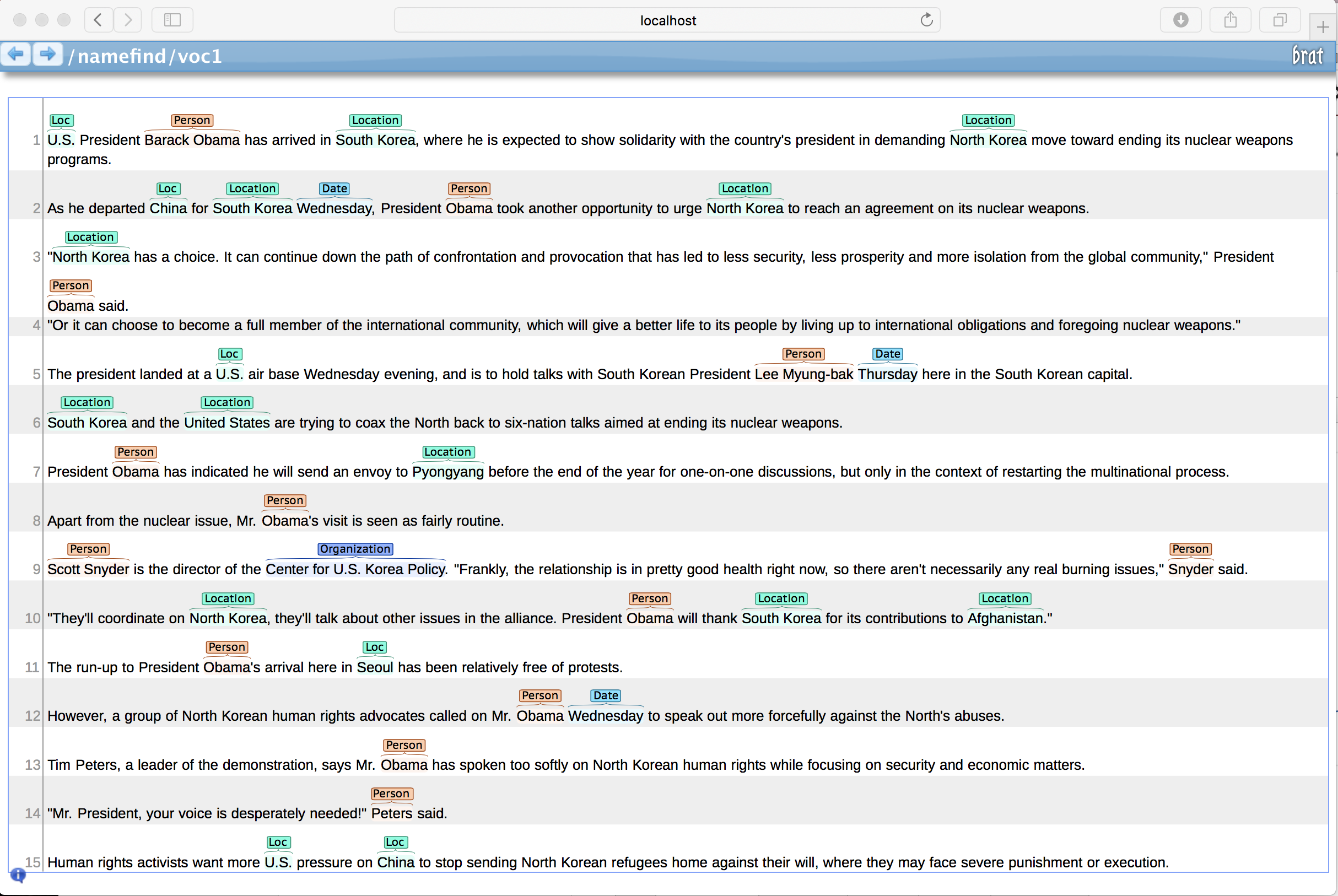
Named Entity Recognition (NER) Example
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.ResultExtractor;
public class NERExample {
public static void main(String[] args) throws Exception {
// Load the NER model
String nerModelFile = "en-namemood.bin";
NameFinderME nameFinder = new NameFinderME(nerModelFile);
// Text to be recognized
String text = "John Smith is a developer at Google. He lives in Mountain View.";
// Recognize the entities
String[] tokens = text.split(" ");
int[][] tokenSpans = new int[tokens.length][2];
for (int i = 0; i < tokens.length; i++) {
ResultExtractor result = nameFinder.extract(tokens, i);
if (result != null) {
tokenSpans[i][0] = result.getStart();
tokenSpans[i][1] = result.getEnd();
}
}
// Print the recognized entities
for (int i = 0; i < tokens.length; i++) {
System.out.println(tokens[i] + ": " + tokenSpans[i][0] + "-" + tokenSpans[i][1]);
}
}
}
This code loads an NER model for English, creates a name finder, and recognizes entities in a sample sentence. The output will be something like:
John / 0-2: Person
Smith / 3-5: ProperNoun
is / 6-7: O
a / 8-9: O
developer / 10-14: Occupation
at / 15-16: O
Google. / 17-20: Organization
He / 21-22: Person
lives / 23-25: O
in / 26-27: O
Mountain View / 28-34: Location
. / 35-36: Punctuation
This shows the recognized entities and their corresponding spans.
Note: You'll need to download the OpenNLP models (POS and NER) for English and add them to your classpath. The models are available from the OpenNLP website.
Java nlp pdf
Here is a detailed response regarding Java NLP (Natural Language Processing) and PDF files:
What is Natural Language Processing (NLP)?
Natural Language Processing (NLP) is a subfield of Artificial Intelligence (AI) that deals with the interaction between computers and humans in natural language. NLP is concerned with developing algorithms, statistical models, and machine learning techniques to analyze, understand, generate, and translate human language, which includes text and speech. The primary goal of NLP is to enable computers to read, write, speak, and comprehend human languages like a native speaker.
What are PDF files?
Portable Document Format (PDF) is a file format developed by Adobe Systems that allows documents to be shared, viewed, and printed across multiple platforms without worrying about compatibility issues. PDFs are widely used for distributing electronic versions of documents, such as academic papers, articles, and reports. PDFs contain text, images, and other multimedia elements, which can be easily searched, bookmarked, and annotated.
How do Java NLP libraries work with PDF files?
Java NLP libraries provide developers with tools to analyze, process, and generate human language data. To work with PDF files, Java NLP libraries need to extract the text from the PDF documents and then apply various NLP techniques, such as tokenization, stemming, lemmatization, named entity recognition (NER), part-of-speech (POS) tagging, sentiment analysis, and topic modeling.
Some popular Java NLP libraries include:
Stanford CoreNLP: A comprehensive library that provides a wide range of NLP tools, including POS tagging, dependency parsing, named entity recognition, and sentence splitting. OpenNLP: An open-source library that offers several NLP components, such as maximum entropy-based tokenization, name entity recognition, and language modeling. Java Text Processing: A lightweight library for processing text data, providing features like tokenization, stemming, lemmatization, and regular expression matching.These libraries can be used to extract text from PDF files using APIs or command-line tools. For example:
Using Stanford CoreNLP, you can use thePDFParser class to parse a PDF file and extract the text content. With OpenNLP, you can employ the PDFToText tool to convert a PDF document into plain text.
Challenges and Applications
Working with Java NLP libraries and PDF files poses several challenges:
Text extraction: Extracting accurate text from PDFs is not always straightforward due to layout complexities, font variations, and formatting inconsistencies. Language detection: Identifying the language(s) used in a PDF document can be challenging, especially when dealing with multilingual texts or documents containing non-standard language varieties.However, overcoming these challenges enables various applications:
Document classification: Classify documents based on their content using machine learning algorithms and NLP techniques. Information retrieval: Search and retrieve specific information from a large corpus of PDF files using indexing and querying tools. Sentiment analysis: Analyze the sentiment (positive, negative, or neutral) expressed in a document to determine its tone and emotional tone. Topic modeling: Identify topics, trends, and relationships within a set of PDF documents using topic modeling techniques.By leveraging Java NLP libraries with PDF files, developers can unlock valuable insights from unstructured text data, driving innovative applications in areas like:
Customer service: Analyze customer feedback and sentiment to improve customer satisfaction. Market research: Identify trends, preferences, and opinions in market surveys and focus groups. Text analytics: Extract key phrases, entities, and relationships from large document collections.In conclusion, Java NLP libraries and PDF files provide a powerful combination for text analysis, processing, and generation. By understanding the challenges and applications, developers can unlock new insights and drive innovative solutions in various domains.