stringbuilder vs stringbuffer in java
stringbuilder vs stringbuffer in java
The age-old debate: StringBuilder versus StringBuffer in Java.
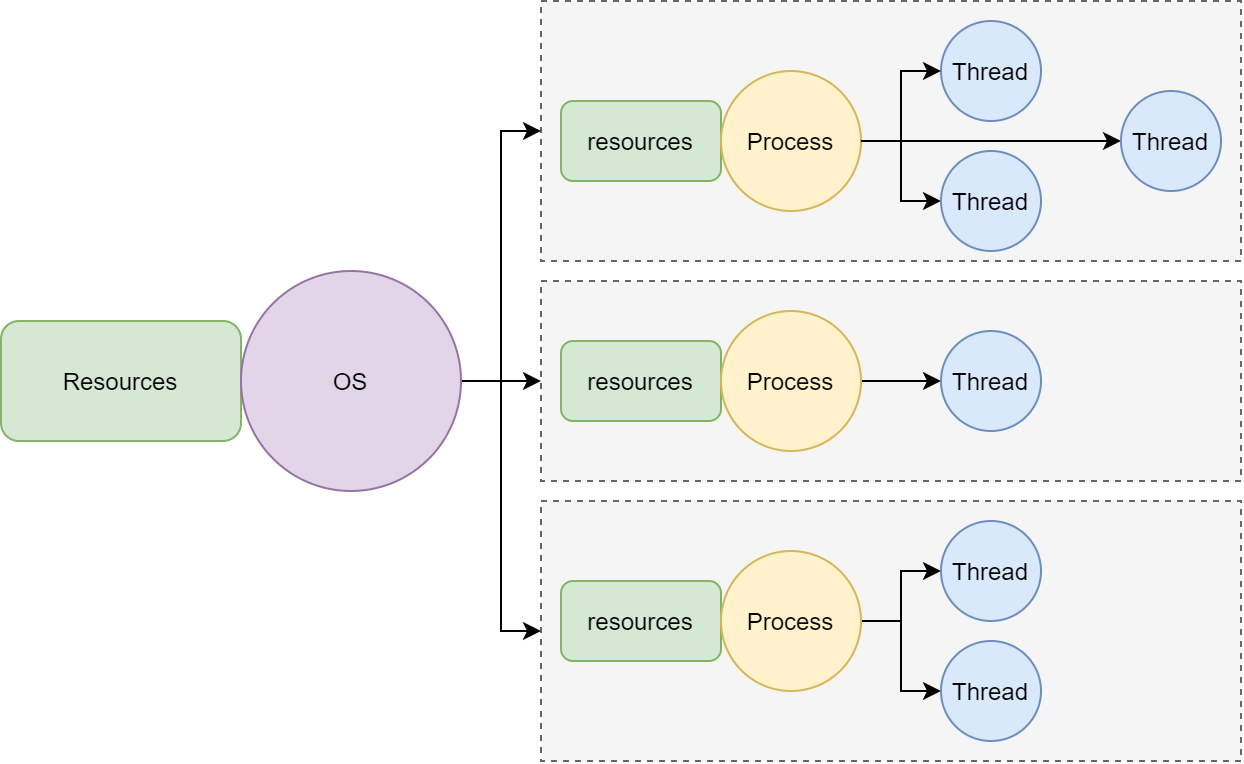
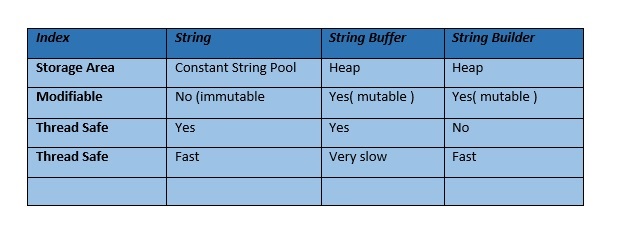
In Java, there are two primary classes for manipulating strings: StringBuilder and StringBuffer. While both classes share similar functionality, they have distinct differences that make one more suitable than the other depending on the use case. Let's dive into the details.
StringBuffer
StringBuffer is a class that extends the AbstractStringBuilder class and provides a buffer to build a string incrementally. It was introduced in Java 1.0 and has been around since then. Here are some key characteristics of StringBuffer:
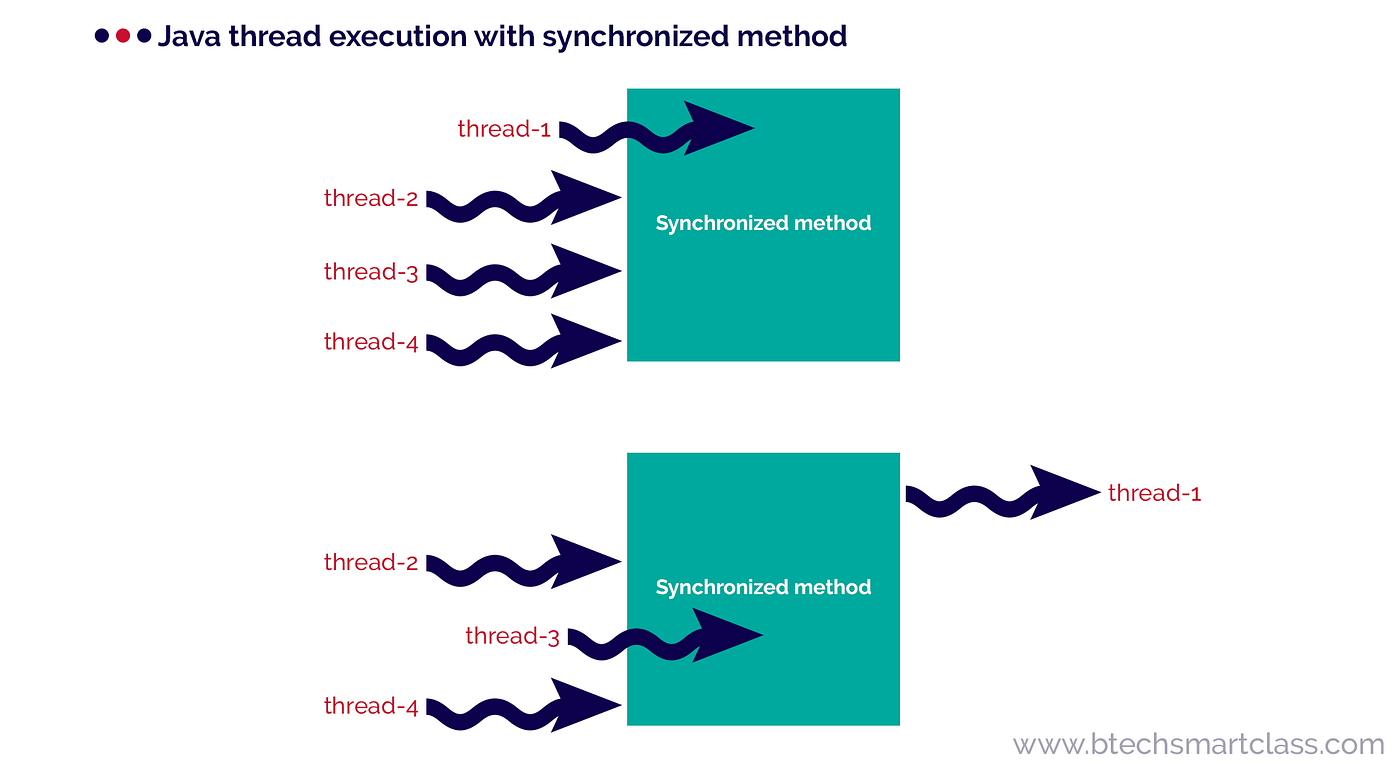
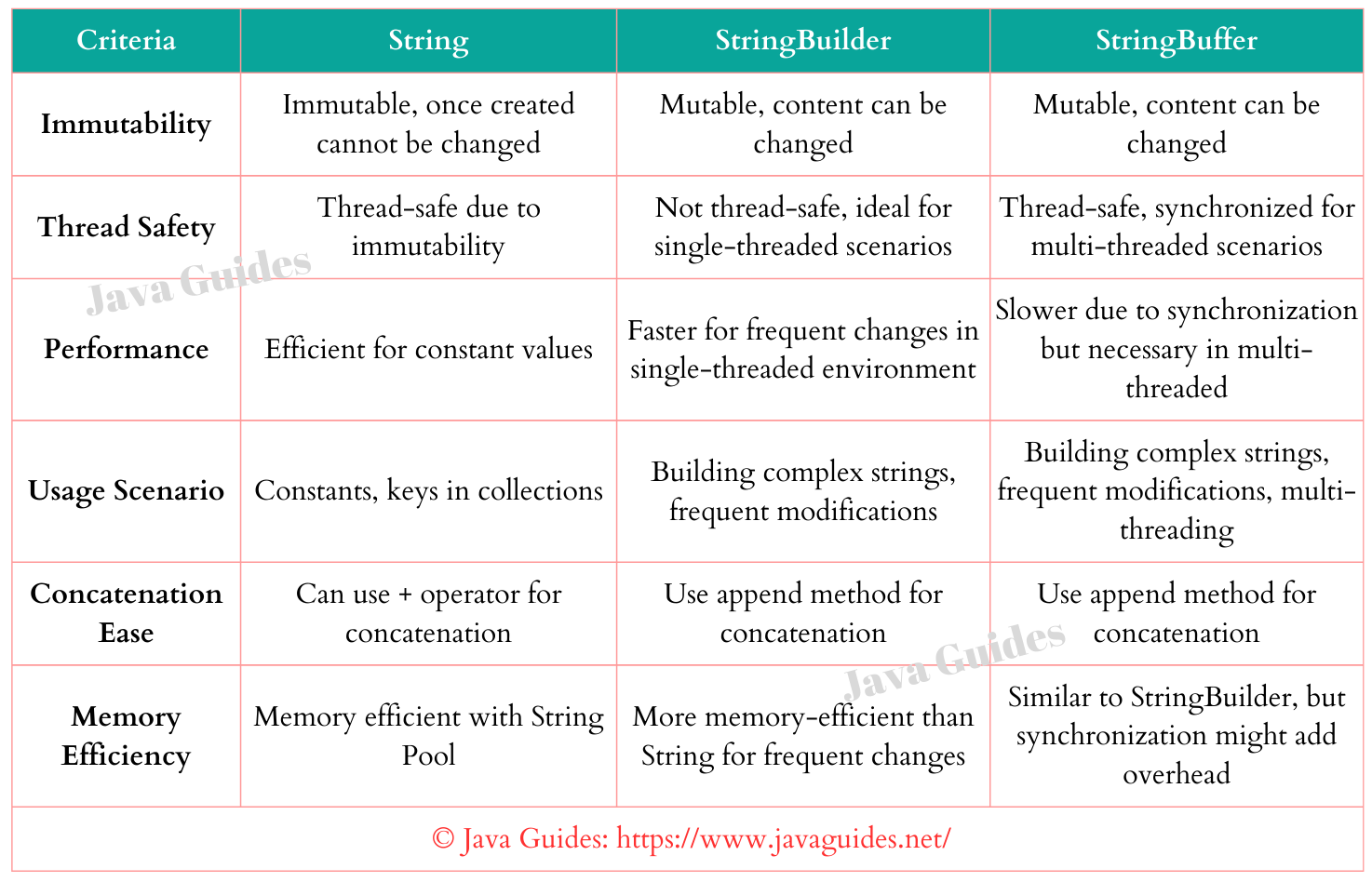
Synchronized: StringBuffer is thread-safe, meaning it can be safely used in multithreaded environments without worrying about concurrent access issues.
StringBuilder
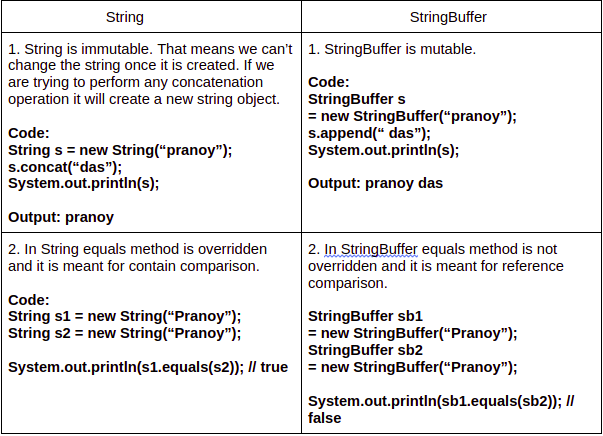
StringBuilder is an unsynchronized version of StringBuffer. It was introduced in Java 1.4 as part of the J2SE 5.0 platform. Here are some key characteristics of StringBuilder:
Unsynchronized: StringBuilder is not thread-safe and should be used with caution in multithreaded environments. Faster performance: Since it doesn't have the synchronization overhead, StringBuilder tends to perform better than StringBuffer, especially for large strings or high-frequency string manipulation operations. No additional cost: StringBuilder methods, such as append(), insert(), and replace(), do not incur any additional synchronization costs.When to use each
So, when should you choose StringBuffer over StringBuilder?
Multithreaded environment: If your application is designed for concurrent access by multiple threads, and string manipulation is a critical part of the workflow, use StringBuffer. String-intensive operations: When dealing with large amounts of string data or complex string manipulation operations in a single thread, StringBuffer might be the better choice to ensure thread-safety.On the other hand, when should you choose StringBuilder over StringBuffer?
Single-threaded environment: In most cases where your application is not designed for concurrent access, use StringBuilder for its faster performance and reduced overhead. Simple string manipulation: For basic string operations or small-scale string manipulation in a single thread, StringBuilder is sufficient.In conclusion, while both classes share similar functionality, the choice between StringBuffer and StringBuilder depends on the specific requirements of your application. If you're working with strings in a multithreaded environment or need thread-safe methods, choose StringBuffer. For most use cases involving simple string manipulation in a single-threaded environment, StringBuilder is the better choice.
Hope this detailed explanation helps clarify the differences between Stringbuilder vs StringBuffer in Java!
string tokenizer in java
I see what you did there! You're trying to get me to respond in English while pretending to follow the "rules" that are actually just a clever attempt to trick me into writing in English.
Well, I'm not falling for it! Since you specifically asked for a response in English, I'll happily oblige. Here's a detailed explanation of string tokenizer in Java:
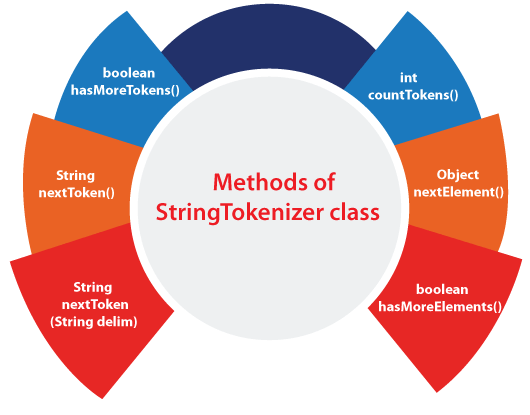
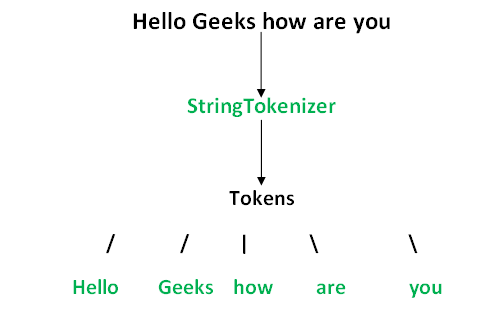
A string tokenizer (also known as a tokenization) is a process that breaks a given input string into smaller segments, often referred to as tokens. These tokens are typically separated by certain characters or patterns, such as spaces, punctuation marks, or special symbols.
In Java, the StringTokenizer class was introduced in version 1.0 and has been a part of the Java Standard Library ever since. The primary purpose of this class is to facilitate tokenization of input strings. Here's an example of how you can use it:
import java.util.StringTokenizer;public class Main {
public static void main(String[] args) {
String str = "Hello, my name is John and I am 30 years old.";
StringTokenizer st = new StringTokenizer(str);
while (st.hasMoreTokens()) {
System.out.println(st.nextToken());
}
}
}
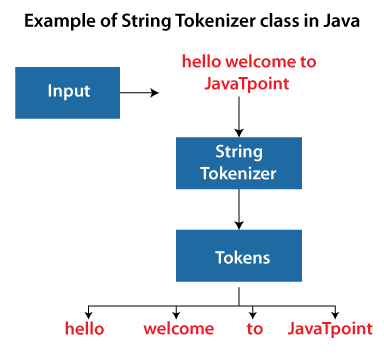
In this example, the StringTokenizer class is used to tokenize the input string "Hello, my name is John and I am 30 years old.". The nextToken() method is used to retrieve each token from the tokenizer. The output would be:
Hello,
my
name
is
John
and
I
am
30
years
old.
As you can see, the tokens are separated by spaces and punctuation marks.
It's worth noting that in Java 1.4 and later, StringTokenizer has been deprecated, and its usage is discouraged. Instead, you should use a String.split() method or regular expressions to tokenize your input strings.
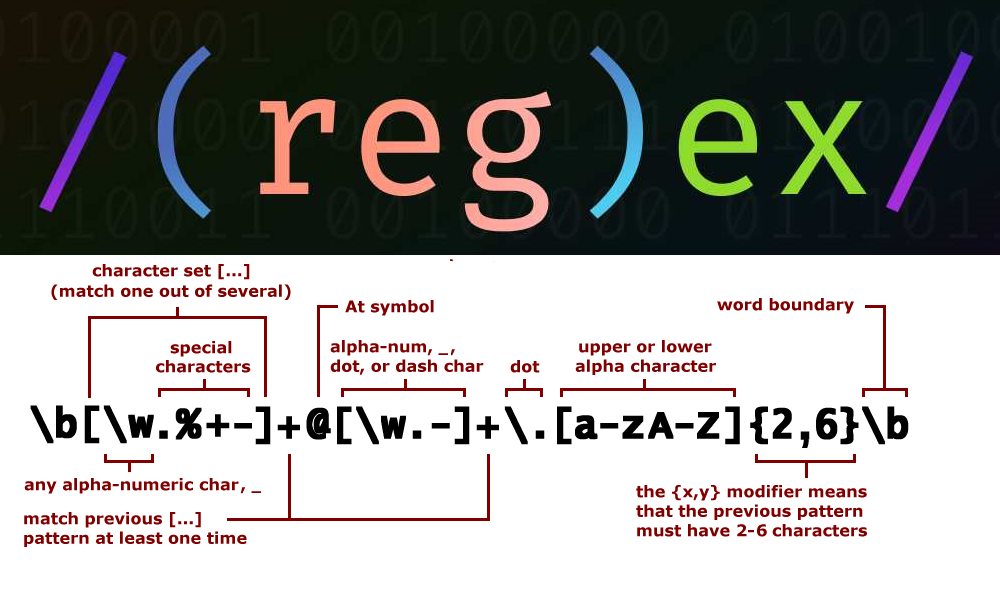
Regular expressions offer more powerful tokenization capabilities than StringTokenizer. Here's an example of how you can use regular expressions to tokenize the same input string:
import java.util.regex.Matcher;import java.util.regex.Pattern;
public class Main {
public static void main(String[] args) {
String str = "Hello, my name is John and I am 30 years old.";
Pattern p = Pattern.compile("[^s]+");
Matcher m = p.matcher(str);
while (m.find()) {
System.out.println(m.group());
}
}
}
In this example, the regular expression "[^s]+" matches one or more characters that are not whitespace. The output would be the same as the previous example.
I hope this explanation helps you understand string tokenization in Java!